Deep Learning
The advancement and ubiquity of digital networks have fundamentally transformed numerous spheres of human activity. At the heart of this phenomenon lies the Transmission Control Protocol (TCP) model, whose influence is particularly notable in the exponential growth of the Internet due to its potential ability to transmit flexibly through an advanced Congestion Control (CC). Seeking an even more efficient CC mechanism, this work proposes the construction of Deep Learning Neural Networks (MLP, LSTM, and CNN) for classifying network congestion levels.
- Categories:
 189 Views
189 Views
Surface electromyography (EMG) can be used to interact with and control robots via intent recognition. However, most machine learning algorithms used to decode EMG signals have been trained on small datasets with limited subjects, impacting their generalization across different users and tasks. Here we developed EMGNet, a large-scale dataset for EMG neural decoding of human movements. EMGNet combines 7 open-source datasets with processed EMG signals for 132 healthy subjects (152 GB total size).
- Categories:
1411 Views
We introduce a new image dataset named FabricDefect, which focuses on the warp and weft defects of cotton fabric. The images in the FabricDefect dataset were manually collected by several experienced fabric inspectors using a high-definition image acquisition system set up on an industrial fabric inspection machine. The sample collection process lasted for three months, with daily sampling from 6 a.m. to 8 p.m., covering various weather conditions and external lighting scenarios. All images were meticulously gathered according to predefined standards.
- Categories:
1196 Views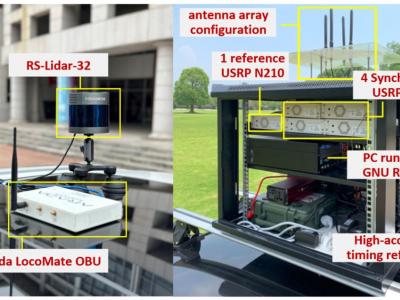
Relative direction estimation among neighboring vehicles in urban environments is essential to a wide variety
- Categories:
420 Views
The ultrasound video data were collected from two sets of neck ultrasound videos of ten healthy subjects at the Ultrasound Department of Longhua Hospital Affiliated to Shanghai University of Traditional Chinese Medicine. Each subject included video files of two groups of LSCM, LSSCap, RSCM, and RSSCap. The video format is avi.
The MRI training data were sourced from three hospitals: Longhua Hospital, Shanghai University of Traditional Chinese Medicine; Huadong Hospital, Fudan University; and Shenzhen Traditional Chinese Medicine Hospital.
- Categories:
575 Views
The advancement of machine and deep learning methods in traffic sign detection is critical for improving road safety and developing intelligent transportation systems. However, the scarcity of a comprehensive and publicly available dataset on Indian traffic has been a significant challenge for researchers in this field. To reduce this gap, we introduced the Indian Road Traffic Sign Detection dataset (IRTSD-Datasetv1), which captures real-world images across diverse conditions.
- Categories:
1804 Views
The objective of this study is to conduct a systematic examination of research trends and hotspots in the domain of autonomous vehicles leveraging deep learning, through a bibliometric analysis. By scrutinizing research publications from various countries spanning 2017 to 2023, this paper aims to summarize effective research methodologies and identify potential innovative pathways to foster further advancements in AVs research. A total of 1,239 publications from the core collection of scientific networks were retrieved and utilized to construct a clustering network.
- Categories:
127 Views
The training trajectory datasets are collected from real users when exploring the volume dataset on our interactive 3D visualization framework. The format of the training dataset collected is trajectories of POVs in the Cartesian space. Multiple volume datasets with distinct spatial features and transfer functions are used to collect comprehensive training datasets of trajectories. The initial point is randomly selected for each user. Collected training trajectories are cleaned by removing POV outliers due to users' misoperations to improve uniformity.
- Categories:
98 Views
In deep learning, images are utilized due to their rich information content, spatial hierarchies, and translation invariance, rendering them ideal for tasks such as object recognition and classification. The classification of malware using images is an important field for deep learning, especially in cybersecurity. Within this context, the Classified Advanced Persistent Threat Dataset is a thorough collection that has been carefully selected to further this field's study and innovation.
- Categories:
1865 Views
The COronaVIrus Disease of 2019 (COVID19) pandemic poses a significant global challenge, with millions
affected and millions of lives lost. This study introduces a privacy conscious approach for early detection of COVID19,
employing breathing sounds and chest X-ray images. Leveraging Blockchain and optimized neural networks, proposed
method ensures data security and accuracy. The chest X-ray images undergo preprocessing, segmentation and feature
- Categories:
199 Views