classification


This dataset comprises 32-bit floating-point SAR images in TIFF format, capturing coastal regions. It includes corresponding ground truth masks that differentiate between land and water areas. The covered regions include the Netherlands, London, Ireland, Spain, France, Lisbon, the USA, India, Africa, and Italy. The SAR images were acquired in Interferometric Wide (IW) mode with dual polarization at a spatial resolution of 10m × 10m.
- Categories:
 309 Views
309 Views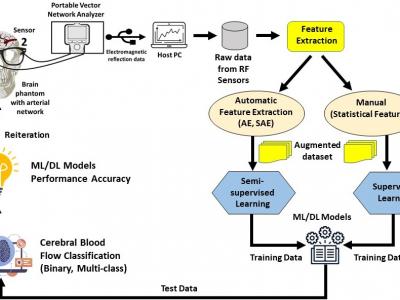
This dataset provides measurements of cerebral blood flow using Radio Frequency (RF) sensors operating in the Ultra-Wideband (UWB) frequency range, enabling non-invasive monitoring of cerebral hemodynamics. It includes blood flow feature data from two arterial networks, Arterial Network A and Arterial Network B. Statistical features were manually extracted from the RF sensor data, while autonomous feature extraction was performed using a Stacked Autoencoder (SAE) with architectures such as 32-16-32, 64-32-16-32-64, and 128-64-32-16-32-64-128.
- Categories:
212 Views
Please cite the following paper when using this dataset:
Vanessa Su and Nirmalya Thakur, “COVID-19 on YouTube: A Data-Driven Analysis of Sentiment, Toxicity, and Content Recommendations”, Proceedings of the IEEE 15th Annual Computing and Communication Workshop and Conference 2025, Las Vegas, USA, Jan 06-08, 2025 (Paper accepted for publication, Preprint: https://arxiv.org/abs/2412.17180).
Abstract:
- Categories:
156 Views
As various modalities of genomic data are accumulating, methods to integrate across multi-omics datasets are becoming important. Error-correcting output codes (ECOC) is an ensemble learning strategy for solving a multiclass problem thru a decoding process that aggregates the predictions of multiple classifiers. Thus, it lends itself naturally to aggregating predictions across multiple views as well. We applied the ECOC to multi-view learning to see if this strategy can enhance classifier performance as compared to traditional techniques.
- Categories:
55 Views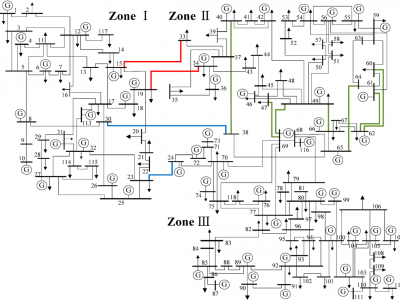
This dataset consists of high-dimensional data streams collected from a cyber-physical 118-bus power system, offering a valuable resource for fault diagnosis and classification in large-scale smart grids.
- Categories:
738 Views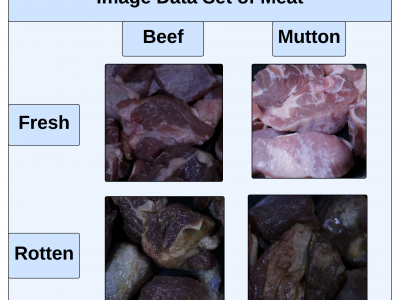
This paper presents an innovative Internet of Things (IoT) system that integrates gas sensors and a custom Convolutional Neural Network (CNN) to classify the freshness and species of beef and mutton in real time. The CNN, trained on 9,928 images, achieved 99% accuracy, outperforming models like ResNet-50, SVM, and KNN. The system uses three gas sensors (MQ135, MQ4, MQ136) to detect gases such as ammonia, methane, and hydrogen sulfide, which indicate meat spoilage.
- Categories:
663 Views
To download this dataset without purchasing an IEEE Dataport subscription, please visit: https://zenodo.org/records/13896353
Please cite the following paper when using this dataset:
- Categories:
1067 Views
To download the dataset without purchasing an IEEE Dataport subscription, please visit: https://zenodo.org/records/13738598
Please cite the following paper when using this dataset:
- Categories:
1365 Views
Recently, combinatorial interaction strategies have a large spectrum as black box strategies for testing software and hardware. This paper discusses a novel adoption of a combinatorial interaction strategy to generate a sparse combinatorial data table (SCDT) for machine learning. Unlike test data generation strategies, in which the t-way tuples synthesize into a test case, the proposed SCDT requires analyzing instances against their corresponding tuples to generate a systematic learning dataset.
- Categories:
151 Views