classification

Problems related to ventral hernia are very common, and evaluating them using computational methods can assist in selecting the most appropriate treatment. This study collected data from over 3500 patients from different European countries observed during last 11 years (2012-2022), which were collected by specialists in hernia surgery. The majority of patients underwent standard surgical procedures, with a growing trend towards robotic surgery. This paper focuses on statistically evaluating the treatment methods in relation to patient age, body mass index (BMI), and the type of repair.
- Categories:
 251 Views
251 Views
Around from 12th century MODI script was used to write Indian languages as Marathi, Hindi, and Gujarati etc. It was used as administrative script from 17th century to mid of 19th century in Maharashtra state (India). At present, MODI script users are diminishing away, and countable persons can understand the MODI script. The preserved archaic historical MODI handwritten documents contained important and rare cultural, historic, and administrative kind of information which is usable in present-days.
- Categories:
790 Views
MODI script was used to write Indian languages as Marathi, Hindi, and Gujarati etc. from 12th century. From 17th century to mid of 19th century MODI was used as administrative script in Maharashtra state (India). Now a days, MODI script users are diminishing away, and countable persons can understand the MODI script. The archaic historical MODI handwritten documents contained important and rare cultural, historic, and administrative type of information which is usable in current era.
- Categories:
654 Views
The recording data include the following anthropometries: age (AG), weight (WE), height (HE), body mass index (BMI), waist circumference (WA), waist/height ratio (WHT), arm circumference (AR), hip circumference (HP), systolic blood pressure (BSY), diastolic blood pressure (DSY), heart rate (HR); the health indicator: glucose (DX); and the following functional fitness parameters: muscle (MM), visceral fat (VF), body fat (BF), and body age (BA). Ageing (AGG) is the ratio AG/BA.
- Categories:
18 Views
Human activity recognition, which involves recognizing human activities from sensor data, has drawn a lot of interest from researchers and practitioners as a result of the advent of smart homes, smart cities, and smart systems. Existing studies on activity recognition mostly concentrate on coarse-grained activities like walking and jumping, while fine-grained activities like eating and drinking are understudied because it is more difficult to recognize fine-grained activities than coarse-grained ones.
- Categories:
655 Views
The data is collected in the form of csv file containing three attributes of X, Y, Z which represents the three coordinates of the graph x, y and z. The csv file is collected from the three signals generated by using a mobile app G sensor logger available publicly from google playstore. The data is generated for the first five Telugu language characters. The data is stored in the form of five folders where each folder represents the respective Telugu character. This dataset can be used for evaluating machine learning algorithms.
- Categories:
133 Views
<p>Anonymized data used in the study of "<span style="font-family: Calibri, sans-serif; font-size: 11pt;">Administrative data processing, Clustering, classification, and association rules, Human factors and ergonomics, Machine learning"</span></p>
- Categories:
275 Views
This is the dataset we collected for the article "Scalable Undersized Dataset RF Classification: Using Convolutional Multistage Training". 17 objects were collected in the laboratory and scanned using a 'cw radar' setup featuring 2x UWB antennas (1 transmit antenna, 1 receive antenna), inside anechoic chamber. There was no clutter added in the experiment.
- Categories:
1552 Views
This dataset is comprised of two parts. In dataset 1, we provide Buddha images, along with positions of hands and faces. Dataset 2 provides Buddha images only and can be used for Buddha statue classification.
- Categories:
474 Views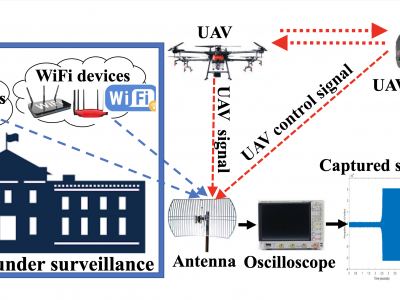
This article presents the details of the Cardinal RF (CardRF) dataset. CardRF is acquired to foster research in RF- based UAV detection and identification or RF fingerprinting. RF signals were collected from UAV controllers, UAV, Bluetooth, and Wi-Fi devices. Signals are collected at both visual line-of-sight and beyond-line-of-sight. The assumptions and procedure for the data acquisition are presented. A detailed explanation of how the data can be utilized is discussed. CardRF is over 65 GB in storage memory.
- Categories:
9839 Views