classification

According to US NOAA, unexploded ordnances (UXO) are ”explosive weapons such as bombs, bullets, shells, grenades, mines, etc. that did not explode when they were employed and still pose a risk of detonation”. UXOs are among the most dangerous, threats to human life, environment and wildlife protection as well as economic development. The risks associated with UXOs do not discriminate based on age, gender, or occupation, posing a danger to anyone unfortunate enough to encounter them.
- Categories:
 1516 Views
1516 Views
This paper presents a dataset of brain Electroencephalogram (EEG) signals created when Malayalam vowels and consonants are spoken. The dataset was created by capturing EEG signals utilizing the OpenBCI Cyton device while a volunteer spoke Malayalam vowels and consonants. It includes recordings obtained from both sub-vocal and vocal. The creation of this dataset aims to support individuals who speak Malayalam and suffer from neurodegenerative diseases.
- Categories:
2592 Views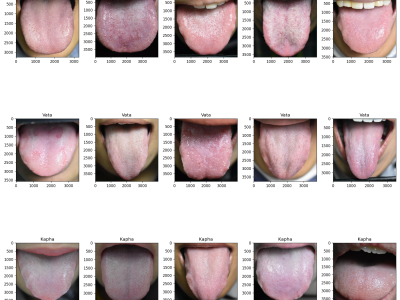
Traditional Thai medicine (TTM) is an increasingly popular treatment option. Tongue diagnosis is a highly efficient method for determining overall health, practiced by TTM practitioners. However, the diagnosis naturally varies depending on the practitioner's expertise. In this work, we propose tongue image analysis using raw pixels and artificial intelligence (AI) to support TTM diagnoses. The target classification of Tri-Dhat consists of three classes: Vata, Pitta, and Kapha. We utilize our own organized genuine datasets collected from our university's TTM hospital.
- Categories:
398 Views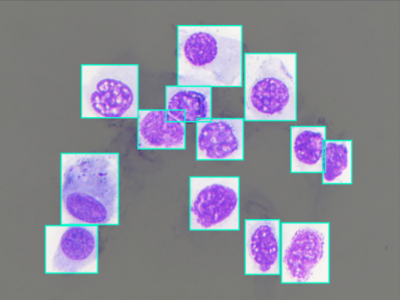
Nasal Cytology, or Rhinology, is the subfield of otolaryngology, focused on the microscope observation of samples of the nasal mucosa, aimed to recognize cells of different types, to spot and diagnose ongoing pathologies. Such methodology can claim good accuracy in diagnosing rhinitis and infections, being very cheap and accessible without any instrument more complex than a microscope, even optical ones.
- Categories:
837 Views
This paper introduces a dataset capturing brain signals generated by the recognition of 100 Malayalam words, accompanied by their English translations. The dataset encompasses recordings acquired from both vocal and sub-vocal modalities for the Malayalam vocabulary. For the English equivalents, solely vocal signals were collected. This dataset is created to help Malayalam speaking patients with neuro-degenerative diseases.
- Categories:
2860 Views
This dataset contains both the artificial and real flower images of bramble flowers. The real images were taken with a realsense D435 camera inside the West Virginia University greenhouse. All the flowers are annotated in YOLO format with bounding box and class name. The trained weights after training also have been provided. They can be used with the python script provided to detect the bramble flowers. Also the classifier can classify whether the flowers center is visible or hidden which will be helpful in precision pollination projects.
- Categories:
474 Views
AIR-RS-DB: A dataset for classifying Spontaneous and Read Speech
A set of 1028 audio files generated from 7 mp3 files downloaded from All India Radio. https://newsonair.gov.in/ and converted into wav and then speaker diarized is using https://huggingface.co/pyannote/speaker-diarization (pyannote/speaker-diarization@2022072,model) and derive 1028 audio files.
- Categories:
138 Views
<p>Ten individuals in good health were enlisted to execute 16 distinct movements involving the wrist and fingers in real-time. Before commencing the experimental procedure, explicit consent was obtained from each participant. Participants were informed that they had the option to withdraw from the study at any point during the experimental session. The experimental protocol adhered to the principles outlined in the Declaration of Helsinki and received approval from the local ethics committee at the National University of Sciences and Technology, Islamabad, Pakistan.
- Categories:
136 Views
Lantana flower, originally known as a parasitic and poisonous plant, is expansive to fill many livestock fields. Lantana data sets are open source and can be used by many researchers to create models with higher accuracy. currently the accuracy using this dataset has reached 99.8% using k-NN and preceded by feature extraction using VGG-16 Lantana flower, originally known as a parasitic and poisonous plant, is expansive to fill many livestock fields. Lantana data sets are open source and can be used by many researchers to create models with higher accuracy.
- Categories:
206 Views
Thailand's national development relies on higher education, posing challenges for the government to enhance graduate competence. High dropout rates impact education quality and student welfare, necessitating a comprehensive study. This research collects a dataset on student dropout and utilizes classification models to predict dropout likelihood at Rajamangala University of Technology Thanyaburi (RMUTT), Thailand. The dataset includes 2,137 undergraduate students from 2013 to 2019 and follows the CRISP-DM model, utilizing internal data sources from ARIT.
- Categories:
453 Views