Security

Our DeepCoAST dataset specifically explores the vulnerabilities of various traffic-splitting Website Fingerprinting (WF) Defenses, such as TrafficSliver, HyWF, and CoMPS. Our dataset comprises defended traces generated from the BigEnough dataset, which includes Tor cell trace instances of 95 websites, each represented by 200 instances collected under the standard browser security level. We simulated the traffic-splitting defenses assuming there are two split traces from the vanilla trace.
- Categories:
 114 Views
114 Views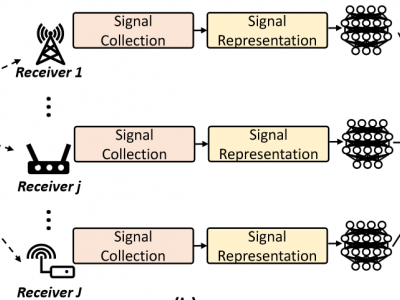
Radio frequency fingerprint identification (RFFI) is an emerging device authentication technique, which exploits the hardware characteristics of the RF front-end as device identifiers. The receiver hardware impairments interfere with the feature extraction of transmitter impairments, but their effect and mitigation have not been comprehensively studied. In this paper, we propose a receiver-agnostic RFFI system by employing adversarial training to learn the receiver-independent features.
- Categories:
756 Views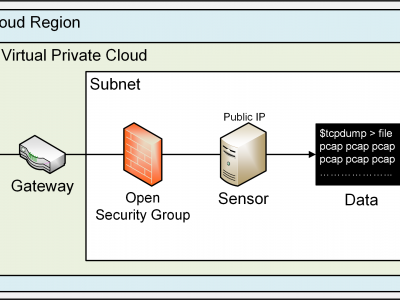
This dataset results from a 47-day Cloud Telescope Internet Background Radiation collection experiment conducted during the months of August and September 2023. A total amount of 260 EC2 instances (sensors) were deployed across all the 26 commercially available AWS regions at the time, 10 sensors per region. A Cloud Telescope sensor does not serve information. All traffic arriving to the sensor is unsolicited, and potentially malicious. Sensors were configured to allow all unsolicited traffic.
- Categories:
565 Views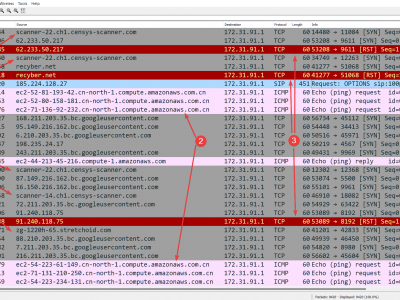
This dataset results from a month-long cloud-based Internet Background Radiation observation conducted in May 2023.
A sensor fleet comprised of 26 EC2 compute instances was deployed within Amazon Web Services across their 26 commercially available regions, 1 sensor per region.
The dataset contains 21,856,713 incoming packets, out of which 17,008,753 are TCP datagrams, 3,076,855 are ICMP packets and the remainder, 1,770,418 are UDP messages.
- Categories:
604 Views
This dataset aims to provide researchers with the essential information to aid in the development and improvement surrounding system call pattern detection for crypto ransomware on Android.
Our dataset provides two sets of extracted and formatted system call logs. The first set consists of system call logs collected from 213 crypto ransomware and the second set consist of 502 benign Android applications.
- Categories:
531 Views
This shows an example run of LUMEN and its efficiency in computation time, verification time, and proof size ran 100 times under the parameters of alpha = 512, d = 16, p = 64. LUMEN is a novel set of algorithms generating efficient and transparent zk-SNARKs: LUMEN consists of a recursive polynomial commitment scheme and a new interactive polynomial oracle proof protocol, which is compiled into efficient and transparent zk-SNARKs with linear proof computation and verification time.
- Categories:
4 Views
The Reflection Server Tuning dataset contains HiPerConTracer latency measurements performed in a lab setup. The purpose of the dataset is to measure the latency and jitter effects of firewalls and Linux kernel tuning.
- Categories:
264 Views
This paper presents a deep learning model for fast and accurate radar detection and pixel-level localization of large concealed metallic weapons on pedestrians walking along a sidewalk. The considered radar is stationary, with a multi-beam antenna operating at 30 GHz with 6 GHz bandwidth. A large modeled data set has been generated by running 2155 2D-FDFD simulations of torso cross sections of persons walking toward the radar in various scenarios.
- Categories:
15 Views
Securing systems with limited resources is crucial for deployment and should not be compromised for other performance metrics like area and throughput. Physically Unclonable Functions (PUFs) emerge as a cost-effective solution for various security applications, such as preventing IC counterfeiting and enabling lightweight authentication. In the realm of memory-based PUFs, the physical variations of available memory systems, such as DRAM or SRAM, are exploited to derive an intrinsic response based on the accessed data row.
- Categories:
337 ViewsThe Army Cyber Institute (ACI) Internet of Things (IoT) Network Traffic Dataset 2023 (ACI-IoT-2023) is a novel dataset tailored for machine learning (ML) applications in the realm of IoT network security. This effort focuses on delivering a distinctive and realistic dataset designed to train and evaluate ML models for IoT network environments. By addressing a gap in existing resources, this dataset aims to propel advancements in ML-based solutions, ultimately fortifying the security of IoT operations.
- Categories:
5975 Views