Security

This dataset comprises qualitative and quantitative data collected from a comprehensive study evaluating the prevalence and types of social engineering vulnerabilities within Tanzanian higher learning institutions. The data was gathered through surveys and structured interviews with 395 participants, including students, academic staff, and administrative staff.
- Categories:
 622 Views
622 Views
There are parts of datasets used in paper <ADFLOW: Integrated and Comprehensive Ad Detection Considering Relationships Among Webpage Elements>, including SITE-D/IMG-D/TEXT-D and some PageGraphs extracted from websites in SITE-D.
The IMG-D dataset is large, and we have not yet finished organizing it, so it only includes a portion. Similarly, due to the extensive size of the entire PageGraph dataset used in our experiments, we have only uploaded the PageGraph of a few hundred websites.
- Categories:
148 Views
Anomaly detection in Phasor Measurement Unit (PMU) data requires high-quality, realistic labeled datasets for algorithm training and validation. Obtaining real field labelled data is challenging due to privacy, security concerns, and the rarity of certain anomalies, making a robust testbed indispensable. This paper presents the development and implementation of a Hardware-in-the-Loop (HIL) Synchrophasor Testbed designed for realistic data generation for testing and validating PMU anomaly detection algorithms.
- Categories:
1510 Views
This dataset is generated for the purpose of developing and testing attestation techniques for IoT devices. The dataset consists of RAM traces for eight different firmwares including traces for running the legitimate firmware as well as tampered versions of the firmwares. we upload the firmware onto the IoT device and allow it to operate for a predefined time period of 300 seconds. Throughout the device's normal operation, we utilize the gateway node to collect numerous RAM trace samples, each comprising 2048 bytes, with randomized intervals between consecutive samples.
- Categories:
175 Views
This dataset serves as replication package of the article "Migrating Software Systems towards Post-Quantum Cryptography - A Systematic Literature Review".
In the article, we conducted a systematic literature review which contains different phases of the search and selection procedure.
These different stages are described in detail by this replication package in order to reproduce our results.
- Categories:
106 Views
This dataset comprises over 38,000 seed inputs generated from a range of Large Language Models (LLMs), including ChatGPT-3.5, ChatGPT-4, Claude-Opus, Claude-Instant, and Gemini Pro 1.0, specifically designed for the application in fuzzing Python functions. These seeds were produced as part of a study evaluating the utility of LLMs in automating the creation of effective fuzzing inputs, a method crucial for uncovering software defects in the Python programming environment where traditional methods show limitations.
- Categories:
231 Views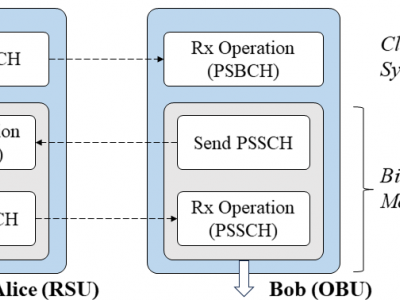
To test the reciprocity of V2X channel, bidirectional channel state information (CSI) measurement is conducted between Alice (RSU) and Bob (OBU) through PSSCH signal. We utilized two USRP X310 SDR platforms equipped with the CBX daughter board as Alice and Bob. Despite the designed fast USRP transceiver switching, there is a signal transmission delay of approximately 0.3 ms, resulting in a gap of about 4 to 5 symbols in the PSSCH subframe actually received by Alice and Bob.
- Categories:
530 Views
This data reflects the prevalence and adoption of smart devices. The experimental setup to generate the IDSIoT2024 dataset is based on an IoT network configuration consisting of seven smart devices, each contributing to a diverse representation of IoT devices. These include a smartwatch, smartphone, surveillance camera, smart vacuum and mop robot, laptop, smart TV, and smart light. Among these, the laptop serves a dual purpose within the network.
- Categories:
1944 Views
The data was built in order to evaluate behavior of the Word Error Rate (WER) of the adversaries' and victims' Error Correcting Codes for different symbol error probability (channel errors) is affected by different code parameters for the adversaries' Error Correcting Code.
For the non-binary communication channel with a GRS based covert channel WER of the victims' Error Correcting Code are shifted to the right as the minimal distance of the adversaries' Error Correcting Codes decrease.
- Categories:
160 Views
The security of systems with limited resources is essential for deployment and cannot be compromised by other performance metrics such as throughput. Physically Unclonable Functions (PUFs) present a promising, cost-effective solution for various security applications, including IC counterfeiting and lightweight authentication. PUFs, as security blocks, exploit physical variations to extract intrinsic responses based on applied challenges, with Challenge-Response Pairs (CRPs) uniquely defining each device.
- Categories:
402 Views