Image Processing

This dataset accompanies the study “Universal Metrics to Characterize the Performance of Imaging 3D Measurement Systems with a Focus on Static Indoor Scenes” and provides all measurement data, processing scripts, and evaluation code necessary to reproduce the results. It includes raw and processed point cloud data from six state-of-the-art 3D measurement systems, captured under standardized conditions. Additionally, the dataset contains high-speed sensor measurements of the cameras’ active illumination, offering insights into their optical emission characteristics.
- Categories:
 138 Views
138 Views
With the gradual maturity of UAV technology, it can provide extremely powerful support for smart agriculture and precise monitoring. Currently, there is no dataset related to green walnuts in the field of agricultural computer vision. Therefore, in order to promote the algorithm design in the field of agricultural computer vision, we used UAV to collect remote sensing data from 8 walnut sample plots.
- Categories:
192 Views
The dataset comprises images generated using computational fluid dynamics (CFD) simulations for two cases: flow past an elliptic cylinder and flow past an aerofoil. Here are the details:
Elliptic Cylinder Dataset:
Images: 124 for low-speed and 124 for high-speed.
Conditions: Simulated for Reynolds numbers of 200 (low-speed) and 5000 (high-speed).
Aerofoil Dataset:
Images: 250 for low-speed and 250 for high-speed.
Conditions: Simulated under similar Reynolds number settings of 200 and 5000 for laminar and turbulent flows, respectively.
- Categories:
152 Views
The AMD3IR dataset is a large-scale collection of Shortwave Infrared (SWIR) and Longwave Infrared (LWIR) images, designed to advance the ongoing research in the field of drone detection and tracking. It efficiently addresses key challenges such as detecting and distinguishing small airborne objects, differentiating drones from background clutter, and overcoming visibility limitations present in conventional imaging. The dataset comprises 20,865 SWIR images with 24,994 annotated drones and 8,696 LWIR images with 10,400 annotated drones, featuring various UAV models.
- Categories:
535 Views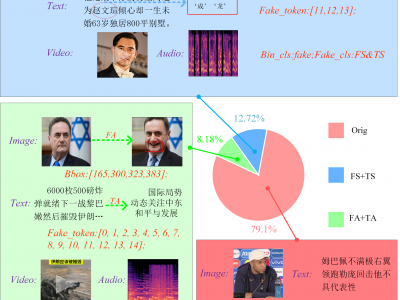
DLSF is the first dedicated dataset for Text-Image Synchronization Forgery (TISF) in multimodal media. The source data for this dataset is scraped from the Chinese news aggregation platform, Toutiao. This dataset includes extensive text, image, and audio-video data from news articles involving politicians and celebrities, featuring samples of both entity-level and attribute-level TISF. It provides comprehensive annotations, including labels for text-image authenticity, types of TISF, image forgery regions, and text forgery tokens.
- Categories:
86 Views
Abstract
- Categories:
767 Views
Addressing the limitations and inconveniences imposed by the randomness in moiré pattern generation on deep learning model training, we have constructed the SynMoiré dataset through a synthetic approach to generate moiré images. The construction process involves resampling the original images into an RGB sub-pixel format, applying random projection transformations, radial distortions, and Gaussian filtering to simulate camera effects.
- Categories:
18 Views
Doppler time-of-flight (Do-ToF) imaging has recently attracted significant attention due to its high-resolution capabilities for measuring radial velocity. However, a challenge arises when the back-reflected signal received by pixels switches between a moving object and a stationary background, leading to the appearance of edge artifacts in the velocity images. To address this issue, we propose a per-pixel gradient-based method for identifying and correcting these artifacts.
- Categories:
20 Views
- Categories:
16 Views
To evaluate SARNet’s generalization, we captured a real-world stereo dataset in Guangzhou using a binocular camera. The dataset includes diverse urban and natural scenes to assess SARNet’s performance beyond synthetic and benchmark datasets. Fig. 7 illustrates SARNet’s predictions on real-world scenes, KITTI 2012, and KITTI 2015. Experimental results demonstrate that SARNet generates clear and consistent disparity maps across both smooth and complex regions, highlighting its robustness in real-world depth estimation tasks.
- Categories:
15 Views