Image Processing

This dataset analyzes rail transit carriage occupancy levels, categorizing crowd density into three distinct classifications. The data collection process involved systematic monitoring of passenger distribution within subway cars during various operational hours, encompassing peak and off-peak periods. Each classification represents different degrees of crowding, providing valuable insights into passenger flow patterns and capacity utilization.
- Categories:
 309 Views
309 Views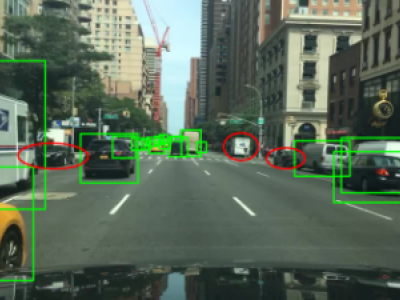
To address common issues in intelligent driving, such as small object missed detection, false detection, and edge segmentation errors, this paper optimizes the YOLOP (You Only Look Once for Panoptic Driving Perception) network and proposes a multi-task perception algorithm based on a MKHA (Multi-Kernel Hybrid Attention) mechanism, named MKHA-YOLOP.
- Categories:
131 Views
The paper presents a novel dataset of continuous, high-quality, contactless fingerprint image streams of the right-hand thumb finger captured from 46 participants, along with synchronized heart rate measurements. The presented dataset was captured with the help of an off-the-shelf monochrome blue-light fingerprint scanner of 500 ppi with 14 fps, accompanied by a commercially available smartwatch for measuring heart rates.
- Categories:
101 Views
As coal mining extends to greater depths, accurately detecting coal seam floor undulations, identifying coal thickness variations, and recognizing complex geological features such as collapse columns has become increasingly essential. These challenges raise higher demands for safety and efficiency in mining operations. This study proposes a dynamic interpretation method for intelligent mining faces based on 3D seismic data to enhance the accuracy of detecting coal seam geological structures.
- Categories:
37 Views

This paper describes a dataset of droplet images captured using the sessile drop technique, intended for applications in wettability analysis, surface characterization, and machine learning model training. The dataset comprises both original and synthetically augmented images to enhance its diversity and robustness for training machine learning models. The original, non-augmented portion of the dataset consists of 420 images of sessile droplets. To increase the dataset size and variability, an augmentation process was applied, generating 1008 additional images.
- Categories:
160 Views
This is a wheat breeding phenotyping and yield dataset, including canopy height (CH, m), canopy volume (CV, m3), and leaf area index (LAI) collected in the field; vegetation index (VI) generated by multispectral data acquired by UAV remote sensing; trial site weather (Weather); and yield (Yield, kg). The data comes from field trials.
Data acquisition and processing are described in the relevant part of the manuscript.
- Categories:
291 Views
Visual tracking has seen remarkable advancements, largely driven by the availability of large-scale training datasets that have enabled the development of highly accurate and robust algorithms. While significant progress has been made in tracking general objects, research on more challenging scenarios, such as tracking camouflaged objects, remains limited. Camouflaged objects, which blend seamlessly with their surroundings or other objects, present unique challenges for detection and tracking in complex environments.
- Categories:
45 Views
Set5, Set11, and Set14 are classic small-scale benchmark datasets widely used for image super-resolution tasks. BSD100 and BSD500 feature complex natural scenes, commonly used for denoising and segmentation research. McM18 is a medical imaging dataset focused on medical image reconstruction. Urban100 emphasizes urban scenes, ideal for evaluating models on high-frequency details and structural textures. These datasets span diverse applications, serving as valuable benchmarks in computer vision research.
- Categories:
24 Views
The file contains merely a small portion of our research results. The particular picture presented showcases the outcomes that were achieved through our fusion method when applied to the TNO test set. The "ir", which is the abbreviation for infrared light image, is characterized by being rich in thermal radiation information. However, it unfortunately has a rather low spatial resolution. On the other hand, the "vis", representing the visible light image, is abundant in scene information. But it has a drawback in that the human targets within it are not so distinctly visible.
- Categories:
214 Views