Image Processing

Image super-resolution (SR) has been an active research problem which has recently received renewed interest due to the introduction of new technologies such as deep learning. However, the lack of suitable criteria to evaluate the SR performance has hindered technology development. In this paper, we fill a gap in the literature by providing the first publicly available database as well as a new image quality assessment (IQA) method specifically designed for assessing the visual quality of super-resolved images (SRIs).
- Categories:
 188 Views
188 Views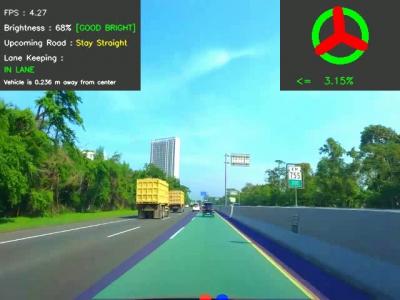
In recent years, the development of driver assistance technology has become a major focus in the automotive industry, particularly in enhancing road detection systems with informative features about the driving environment. These systems aim to provide navigation and improve driving safety. It is crucial for these systems to accurately recognize and understand road environments, especially marked and unmarked roads.
- Categories:
746 Views
Image denoising is an important algorithm in ASIC real-time image processing. Research has found that after cascaded spatial and temporal denoising, video images still exhibit patches and structural noise. To reduce the noise of this type while considering factors such as hardware resource overhead in ASIC implementation, this paper proposes a multi-layer adaptive threshold denoising method based on Non-Local Mean algorithm and pyramid framework.
- Categories:
61 Views
Recent advances in generative visual content have led to a quantum leap in the quality of artificially generated Deepfake content. Especially, diffusion models are causing growing concerns among communities due to their ever-increasing realism. However, quantifying the realism of generated content is still challenging. Existing evaluation metrics, such as Inception Score and Fréchet inception distance, fall short on benchmarking diffusion models due to the versatility of the generated images.
- Categories:
162 Views
This work presents a specialized dataset designed to advance autonomous navigation in hiking trail and off-road natural environments. The dataset comprises over 1,250 images (640x360 pixels) captured using a camera mounted on a tele-operated robot on hiking trails. Images are manually labeled into eight terrain classes: grass, rock, trail, root, structure, tree trunk, vegetation, and rough trail. The dataset is provided in its original form without augmentations or resizing, allowing end-users flexibility in preprocessing.
- Categories:
589 Views
This dataset, titled "Synthetic Sand Boil Dataset for Levee Monitoring: Generated Using DreamBooth Diffusion Models," provides a comprehensive collection of synthetic images designed to facilitate the study and development of semantic segmentation models for sand boil detection in levee systems. Sand boils, a critical factor in levee integrity, pose significant risks during floods, necessitating accurate and efficient monitoring solutions.
- Categories:
342 Views
These are some graphs that record the human ocular electrical signals and ocular impedance signals, each image from top to bottom is a time-frequency graph of the EOG, the EOG signals, the time-frequency graph of the impedance signals, the impedance signals, and the impedance signals, respectively. This dataset is used to train the eye movement detection model.
- Categories:
209 Views
This is the video dataset for SFDM paper. Only the first 30 seconds are to be used. The last 10 seconds are extended so that the trimming of the video does not make each clip end abruptly before 30 seconds.
File naming style: {case study number}{sequence}{clip number}{opt: falsely detected as other sequence}.webm
- Categories:
206 Views
We introduce a new image dataset named FabricDefect, which focuses on the warp and weft defects of cotton fabric. The images in the FabricDefect dataset were manually collected by several experienced fabric inspectors using a high-definition image acquisition system set up on an industrial fabric inspection machine. The sample collection process lasted for three months, with daily sampling from 6 a.m. to 8 p.m., covering various weather conditions and external lighting scenarios. All images were meticulously gathered according to predefined standards.
- Categories:
1145 Views
- Categories:
539 Views