Image Processing

Optical remote sensing images, with their high spatial resolution and wide coverage, have emerged as invaluable tools for landslide analysis. Visual interpretation and manual delimitation of landslide areas in optical remote sensing images by human is labor intensive and inefficient. Automatic delimitation of landslide areas empowered by deep learning methods has drawn tremendous attention in recent years. Mask R-CNN and U-Net are the two most popular deep learning frameworks for image segmentation in computer vision.
- Categories:
 198 Views
198 Views
This dataset is from "One-Stage Cascade Refinement Networks for Infrared Small Target Detection." It includes 427 infrared images and 480 targets (due to the lack of infrared sequences, SIRST also contains infrared images at a wavelength of 950 nm, in addition to shortwave and midwave infrared images). Approximately 90% of the images contain only one target, while about 10% have multiple targets (which may be overlooked in sparse/significant methods due to global unique assumptions).
- Categories:
191 Views
The Reflectance Transformation Imaging dataset consists of 32 images from the squeeze of the inscription "Hymn of Kouretes" or "Hymn of Palaikastron" (fragment A, side A) which is hosted at the Archaeological Museum of Heracleon, Crete. The resulting .PTM file is also available, which opens with the free software RTI Viewer.
- Categories:
254 Views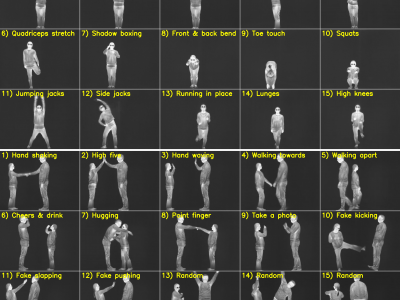
Human pose estimation has applications in numerous fields, including action recognition, human-robot interaction, motion capture, augmented reality, sports analytics, and healthcare. Many datasets and deep learning models are available for human pose estimation within the visible domain. However, challenges such as poor lighting and privacy issues persist. These challenges can be addressed using thermal cameras; nonetheless, only a few annotated thermal human pose datasets are available for training deep learning-based human pose estimation models.
- Categories:
403 Views
Resistance training with elastic bands has been proven to effectively enhance muscle performance, making it an important component of strength and fitness training. However, assessing the intensity of resistance training typically requires large equipment such as isokinetic dynamometers or complex methods like muscle electromyography.
- Categories:
65 Views
Visible and infrared DoFP images. Visible DoFP images were taken by the North Guangwei UMC4A-PU0A Micro DoFP LWIR polarization imager, which consists of an array of wire-grid micro-polarizers, with a resolution of 640 × 512 and a 14 bits depth. Infrared DoFP images were taken by Daheng Imaging MER2-503-36U3M POL DoFP visible polarization imager, which employs a monochromatic quad-polarizer array at a resolution of 2448×2048, an 8 bits depth and a frame rate of 36 frames/s.
- Categories:
96 Views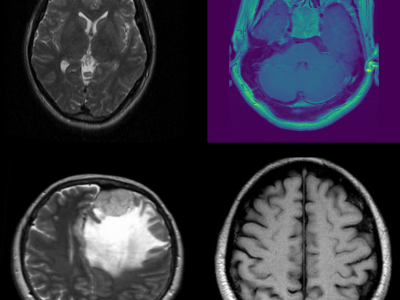
This dataset consists of MRI images of brain tumors, specifically curated for tasks such as brain tumor classification and detection. The dataset includes a variety of tumor types, including gliomas, meningiomas, and glioblastomas, enabling multi-class classification. Each MRI scan is labeled with the corresponding tumor type, providing a comprehensive resource for developing and evaluating machine learning models for medical image analysis. The data can be used to train deep learning algorithms for brain tumor detection, aiding in early diagnosis and treatment planning.
- Categories:
3029 Views
Accurately detecting power line defects under diverse weather conditions is crucial for ensuring power grid reliability and safety. Existing power line inspection datasets, while valuable, often lack the diversity needed for training robust machine learning models, particularly for adverse weather scenarios like fog, rain, and nighttime conditions. This paper addresses this limitation by introducing a novel framework for generating synthetic power line images under diverse weather conditions, thereby enhancing the diversity and robustness of power line inspection systems.
- Categories:
333 Views
This dataset addresses the challenge of limited vocal recordings available in secondary datasets, particularly those that predominantly feature foreign accents and contexts. To enhance the accuracy of our solution tailored for Sri Lankans, we employed primary data-gathering methods.
The dataset comprises vocal recordings from a sample population of youth. Participants were instructed to read three specific sentences designed to capture a range of vocal tones:
- Categories:
208 Views
The Facial Expression Dataset (Sri Lankan) is a culturally specific dataset created to enhance the accuracy of emotion recognition models in Sri Lankan contexts. Existing datasets, often based on foreign samples, fail to account for cultural differences in facial expressions, affecting model performance. This dataset bridges that gap, using high-quality data sourced from over 100 video clips of professional Sri Lankan actors to ensure expressive and clear facial imagery.
- Categories:
590 Views