Image Processing

In the captured image, a drone is seen in flight, displaying its advanced technological features and capabilities. The image highlights the drone's robust design and aerodynamic structure, which are essential for its diverse applications in research and development. Drones, also known as Unmanned Aerial Vehicles (UAVs), are increasingly being utilized in various fields due to their ability to collect data from hard-to-reach or hazardous areas.
- Categories:
 289 Views
289 Views
In recent years, the field of visual tracking has made significant progress with the application of large-scale training datasets. These datasets have supported the development of sophisticated algorithms, enhancing the accuracy and stability of visual object tracking. However, most research has primarily focused on favorable illumination circumstances, neglecting the challenges of tracking in low-ligh environments. In low-light scenes, lighting may change dramatically, targets may lack distinct texture features, and in some scenarios, targets may not be directly observable.
- Categories:
39 Views
The dataset folder is divided into two parts. The first part is the Train dataset, which contains 900 Kvasir-SEG data sets and 550 CVC-ClinicDB data sets, with a total of 1450 training images. image is the original image and masks are labels. The next is the test dataset, which contains the remaining images of Kvasir-SEG and CVC-ClinicDB as the test set, and all images of CVC-ColonDB, ETIS, and CVC-300 as the test set images.
- Categories:
97 Views
The dataset folder is divided into two parts. The first part is the Train dataset, which contains 900 Kvasir-SEG data sets and 550 CVC-ClinicDB data sets, with a total of 1450 training images. image is the original image and masks are labels. The next is the test dataset, which contains the remaining images of Kvasir-SEG and CVC-ClinicDB as the test set, and all images of CVC-ColonDB, ETIS, and CVC-300 as the test set images.
- Categories:
103 Views
The NEU-DET dataset is a collection of images featuring surface defects on hot-rolled steel strips. These defects are categorized into six classes: cracks (cr), inclusions (in), patches (pa), pitted surfaces (ps), rolled-in scale (rs), and scratches (sc). The dataset contains 300 grayscale images for each category, totaling 1800 images, with each image sized at 200×200 pixels.
- Categories:
699 Views
The Railway Surface Defect Detection (RSDDs) dataset was created to enhance the safety and reliability of railway transportation. This dataset comprises two subsets: Type-I RSDDs and Type-II RSDDs, which were collected from express and common/heavy haul railways, respectively. Type-I RSDDs consists of 67 images, each measuring 160×1000 pixels, while Type-II RSDDs includes 128 images, each measuring 55×1250 pixels. These images were captured under various lighting conditions to simulate real-world railway manufacturing and maintenance environments.
- Categories:
175 Views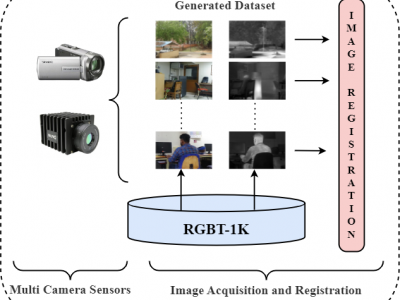
In this dataset, we present a novel RGB-Thermal paired dataset, RGBT-1K, comprising 1,000 image pairs specifically curated to support research in multi-modality image processing. The dataset captures diverse indoor and outdoor scenes under varying lighting conditions, offering a robust benchmark for applications in image enhancement, object detection, and scene analysis. The image acquisition process involved using the FLIR A70 thermal camera and the Sony Handycam HDR-CX405, with the latter positioned atop the thermal camera for precise alignment.
- Categories:
458 Views
IMU-Blur commenced our evaluation by randomly selecting 8350 clear images (aka. backgrounds) from existing image datasets~\cite{zhou2017places,quattoni2009recognizing}. By capturing IMU data during the motion blur induced by the RealSense D455i camera, we synthesized a dataset of 8350 blurred images accompanied by corresponding blur heat maps. Ultimately, this dataset, namely IMU-Blur, contains 6680 triplets for training and 1670 triplets for testing.
- Categories:
30 Views
IMU-Blur commenced our evaluation by randomly selecting 8350 clear images (aka. backgrounds) from existing image datasets~\cite{zhou2017places,quattoni2009recognizing}. By capturing IMU data during the motion blur induced by the RealSense D455i camera, we synthesized a dataset of 8350 blurred images accompanied by corresponding blur heat maps. Ultimately, this dataset, namely IMU-Blur, contains 6680 triplets for training and 1670 triplets for testing.
- Categories:
15 Views
PSP-MP, a subway platform passenger standing position dataset created using Blender software. The dataset includes 200 test scenarios. The IMG directory stores binocular images of the subway platform layer, with a single image resolution of 1280 * 720Pixel and a JPG format. The GT directory stores information such as the standing position, height, and orientation of passengers on the platform layer in the platform coordinate system.
- Categories:
89 Views