Computer Vision

<p>Images from Sentinel 2 for dehazing. Contains 3 folders, one with original images, one with dehazed images at default exponent of 0.8 and the last with failed images with fine tuned exponent (thus becoming successful).</p>
- Categories:
 32 Views
32 Views
Due to the smaller size, low cost, and easy operational features, small unmanned aerial vehicles (SUAVs) have become more popular for various defense as well as civil applications. They can also give threat to national security if intentionally operated by any hostile actor(s). Since all the SUAV targets have a high degree of resemblances in their micro-Doppler (m-D) space, their accurate detection/classification can be highly guaranteed by the appropriate deep convolutional neural network (DCNN) architecture.
- Categories:
6777 Views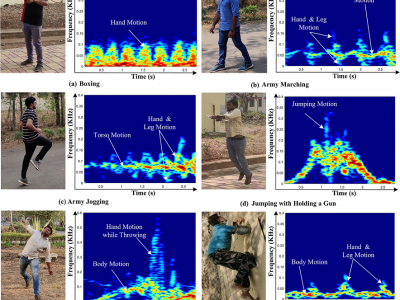
In the view of national security, radar micro-Doppler (m-D) signatures-based recognition of suspicious human activities becomes significant. In connection to this, early detection and warning of terrorist activities at the country borders, protected/secured/guarded places and civilian violent protests is mandatory.
- Categories:
6556 Views
Neuromorphic vision is one of the novel research fields that studies neuromorphic cameras and spiking neural networks (SNNs) for computer vision. Instead of computing on frame-based images, spike events are streamed from neuromorphic cameras, and novel object detection algorithms have to deal with spike events to achieve detection tasks. In this paper, we propose a solution of the novel object detection method with spike events. Spike events are first decoded to event images according to the computational methodology of neuromorphic theory.
- Categories:
113 Views
This dataset contains 1500 images of various cricket umpire hand signs
- Categories:
410 Views
*** The paper published on Multimedia Tools and Applications (Springer) - 2024 ***
*** Title: "SPRITZ-PS: Vlaidation of Synthetic Face Images Using A Large Dataset of Printed Docuemnts"***
*** Authors: Ehsan Nowroozi, Yoosef Habibi, and Mauro Conti ***
----------------------------------------------------------------------------------------------------------
- Categories:
769 Views
Drone based wildfire detection and modeling methods enable high-precision, real-time fire monitoring that is not provided by traditional remote fire monitoring systems, such as satellite imaging. Precise, real-time information enables rapid, effective wildfire intervention and management strategies. Drone systems’ ease of deployment, omnidirectional maneuverability, and robust sensing capabilities make them effective tools for early wildfire detection and evaluation, particularly so in environments that are inconvenient for humans and/or terrestrial vehicles.
- Categories:
22081 Views
This data contains 80 blood cell images with a resolution of 5472×3648. It is mainly a segmentation dataset of five categories of white blood cells, including lymphocytes, basophils, neutrophils, eosinophils and monocytes.
- Categories:
58 Views
RIFIS is an image dataset that illustrates numerous aspects of rice field cultivation utilizing a walk-behind tractor. This dataset includes multiple movies, photos, and annotations. Moreover, location and orientation data are provided for the tractor during video and image recording.
- Categories:
377 Views
Dataset generated with Unreal Engine 4 and Nvidia NDDS. Contains 1500 images of each object: Forklift, pallet, shipping container, barrel, human, paper box, crate, and fence. These 1500 images are split into 500 images from each environment: HDRI and distractors, HDRI with no distractors, and a randomized environment with distractors.
- Categories:
660 Views