Computer Vision

During Printed Circuit Board (PCB) manufacturing, it is critical to dispense the correct amount of conductive glue on the substrate LCP surface before die attachment, as the dispensing of excessive or insufficient glue may cause defects through short circuits or weak die bonding. Therefore it is critical to monitor the amount of the dispensed glue during production.
- Categories:
 441 Views
441 Views
This is a dataset about clustered pop-pepper in Guiyang, China. Some of our depth data are distorted, but generally available. It will be continuously updated in the future.
- Categories:
212 Views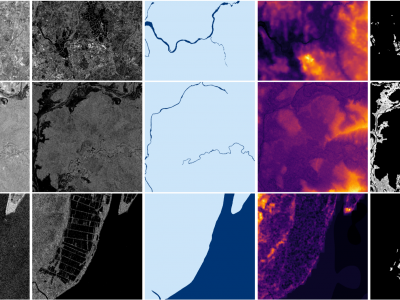
Accurate flood delineation is crucial in many disaster management tasks, including, but not limited to: risk map production and update, impact estimation, claim verification, or planning of countermeasures for disaster risk reduction. Open remote sensing resources such as the data provided by the Copernicus ecosystem enable to carry out this activity, which benefits from frequent revisit times on a global scale. In the last decades, satellite imagery has been successfully applied to flood delineation problems, especially considering Synthetic Aperture Radar (SAR) signals.
- Categories:
2965 Views
TO BE ADDED AFTER PUBLICATION.
- Categories:
41 Views
The C3I Synthetic Human Dataset provides 48 female and 84 male synthetic 3D humans in fbx format generated from iClone 7 Character creator “Realistic Human 100” toolkit with variations in ethnicity, gender, race, age, and clothing. For each of these, it further provides the full-body model with five different facial expressions – Neutral, Angry, Sad, Happy, and Scared. Along with the body models, it also open-sources a data generation pipeline written in python to bring those models into a 3D Computer Graphics tool called Blender.
- Categories:
648 Views
Dataset for segmentation of the defects on the surfaces of the military cartridge cases. The datasets with non-defective, defective and masked image classes of the defective cartridge cases.
- Categories:
357 Views
This open dataset is subject to CC BY-NC-SA 4.0 License. The dataset is intended for scientific research purposes and it cannot be used for commercial purposes. The authors encourage users to use it for public research and as a testbench for private research. Please note that any promotional/marketing material built upon this dataset should be backed by publicly available description of the work leading to the promotional/marketing claims.
- Categories:
2048 Views
Measuring the appearance time slots of characters in videos is still an unsolved problem in computer vision, and the related dataset is insufficient and unextracted. The Character Face In Video (CFIV) dataset provides the labeled appearing time slots for characters of interest for ten video clips on Youtube, two faces per character for training, and a script for downloading each video. Additionally, three videos contain around 100 images per character for evaluating the accuracy of the face recognizer.
- Categories:
328 Views
The dataset contains results of the paper being submitted.
- Categories:
111 Views
This project investigates bias in automatic facial recognition (FR). Specifically, subjects are grouped into predefined subgroups based on gender, ethnicity, and age. We propose a novel image collection called Balanced Faces in the Wild (BFW), which is balanced across eight subgroups (i.e., 800 face images of 100 subjects, each with 25 face samples).
- Categories:
1686 Views