Artificial Intelligence

This collection includes multiple short text classification datasets designed for various natural language processing tasks. It contains several topic classification datasets, such as AG'News, Snippets, and TMNNews, which cover a wide range of topics and domains to evaluate the effectiveness of classification models. Additionally, the collection includes a binary sentiment classification dataset, such as Twitter, aimed at determining positive or negative sentiment in text.
- Categories:
 36 Views
36 Views
To promote the deployment of quadrupedal robots, this study proposes a novel bio-inspired control scheme. Specifically, inspired by the differentiated modalities of the animal's proximal and distal joints, a multi-model fusion scheme is constructed. First, the hip movement in joint space is obtained by a central pattern generator(CPG), whereby motion gaits, including trotting and galloping, are generated by a coupling network. Then, to generate the knee motion, a CPG-driven finite state machine is first proposed to determine the gait state.
- Categories:
37 Views
This dataset contains electromagnetic field (EMF) intensity measurements recorded at half-hour intervals. The dataset spans a continuous timeline, capturing variations in electric field strength in volts per meter (V/m). It serves as a valuable resource for environmental monitoring, predictive modeling, and studying the impacts of EMF exposure. Applications include urban planning, public health assessments, and advanced regression or machine learning modeling.
- Categories:
111 Views
This MATLAB script presents an innovative approach to 5G beamforming prediction using a sequence-based LSTM neural network. Unlike conventional methods that predict only final vectors, this solution provides time-stepped predictions across entire sequences, enabling real-time tracking of dynamic channel conditions. The framework achieves stable training convergence while maintaining physically meaningful performance metrics, including realistic path loss and SNR values.
- Categories:
159 Views
The data was collected by a tester holding a Xiaomi 13 smartphone while walking and collecting data in an underground parking lot covering a 16x70m area. The data includes 5G radio features and geomagnetic field information.
Collection Time: From 09:58 AM to 10:34 AM on July 13, 2024.
Total Samples: 12,800
Training Set (including validation set): 10,240
Test Set: 2,560
- Categories:
107 Views
This paper conducts in-depth research on three text classification tasks: sentiment analysis, offensive language identification, and news topic classification.
- Categories:
23 Views
In this dataset, a human detecting model using with UWB radar technology is presented. Two distinct datasets were created using the UWB radar device, leveraging its dual features. Data collection involved two main scenarios, each containing multiple sub-scenarios. These sub-scenarios varied parameters like the position, distance, angle, and orientation of the human subject relative to the radar. Unlike conventional approaches that rely on signal processing or noise/background removal, this study uniquely emphasizes analyzing raw UWB radar data directly.
- Categories:
611 Views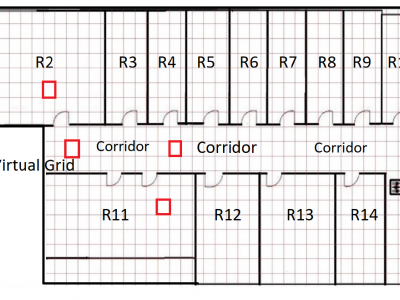
The JU-Impact Radiomap Dataset is a comprehensive dataset designed for research and development in indoor positioning systems. It comprises 5431 instances characterized by readings from 105 static Wi-Fi Access Points (APs) and spans 152 distinct virtual grids. Each virtual grid represents a 1x1 square meter area, derived by dividing a physical floor of a university building into reference coordinate points (x, y). The dataset was collected over a period of 21 days using four mobile devices: Samsung Galaxy Tab, Moto G, Redmi Note 4, and Google Pixel.
- Categories:
160 Views
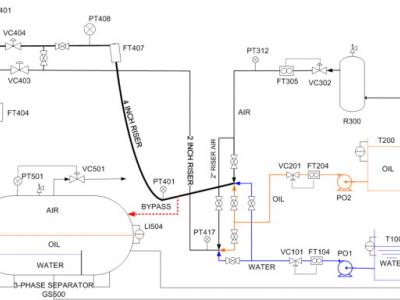
Dateset of the Three-Phase Flow Facility. The Three-phase Flow Facility at Cranfield University is designed to provide a controlled and measured flow rate of water, oil and air to a pressurized system. Fig. 1 shows a simplified sketch of the facility. The test area consists of pipelines with different bore sizes and geometries, and a gas and liquid two-phase separator (0.5 m diameter and 1.2 m high) at the top of a 10.5 m high platform. It can be supplied with single phase of air, water and oil, or a mixture of those fluids, at required rates.
- Categories:
245 Views