Image Processing

Objective: No data currently exist on the reproducibility of photographic food records compared to diet diaries, two commonly used methods to measure habitual dietary intake. Our aim was to examine the reproducibility of diet diaries, photographic food records, and a novel electronic sensor, consisting of counts of chews and swallows using wearable sensors and video analysis, for estimating energy intake.
- Categories:
 353 Views
353 Views
Supplementary material for the paper: 'Adaptive Block Compressive Imaging: towards a real-time and low complexity implementation'
- Categories:
194 Views
The supplementary files of our submitted TIFS paper: "CALPA-NET: Channel-pruning-assisted Deep Residual Network for Steganalysis of Digital Images".
- Categories:
253 Views
This aerial image dataset consists of more than 22,000 independent buildings extracted from aerial images with 0.0075 m spatial resolution and 450 km^2 covering in Christchurch, New Zealand. The most parts of aerial images are down-sampled to 0.3 m ground resolution and cropped into 8,189 non-overlapping tiles with 512* 512. These tiles make up the whole dataset. They are split into three parts: 4,736 tiles for training, 1,036 tiles for validation and 2,416 tiles for testing.
- Categories:
394 Views
This Dataset contains "Pristine" and "Distorted" videos recorded in different places. The
distortions with which the videos were recorded are: "Focus", "Exposure" and "Focus + Exposure".
Those three with low (1), medium (2) and high (3) levels, forming a total of 10 conditions
(including Pristine videos). In addition, distorted videos were exported in three different
qualities according to the H.264 compression format used in the DIGIFORT software, which were:
High Quality (HQ, H.264 at 100%), Medium Quality (MQ, H.264 at 75%) and Low Quality
- Categories:
1245 Views
This paper applies AI (artificial intelligence) technology to analyze low-dose HRCT (High-resolution chest radiography) data in an attempt to detect COVID-19 pneumonia symptoms. A new model structure is proposed with segmentation of anatomical structures on DNNs-based (deep learning neural network) methods, relying on an abundance of labeled data for proper training.
- Categories:
3841 Views
Dataset asscociated with a paper in IEEE Transactions on Pattern Analysis and Machine Intelligence
"The perils and pitfalls of block design for EEG classification experiments"
DOI: 10.1109/TPAMI.2020.2973153
If you use this code or data, please cite the above paper.
- Categories:
1715 Views
- Categories:
409 Views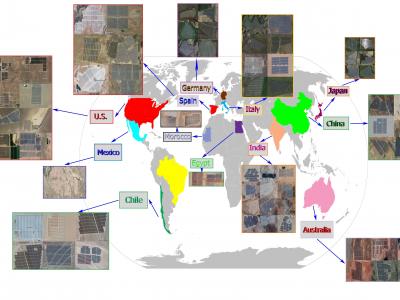
Extracting the boundaries of Photovoltaic (PV) plants is essential in the process of aerial inspection and autonomous monitoring by aerial robots. This method provides a clear delineation of the utility-scale PV plants’ boundaries for PV developers, Operation and Maintenance (O&M) service providers for use in aerial photogrammetry, flight mapping, and path planning during the autonomous monitoring of PV plants.
- Categories:
1466 Views
Accurate information about crop rotation is essential for administrators, managers and various government departments for assessment, monitoring, and management of various resources for crop escalation. Radar remote sensing, because of its all-weather capability and assured uninterrupted data supply can show a substantial part in the evaluation of crop rotation.
- Categories:
937 Views