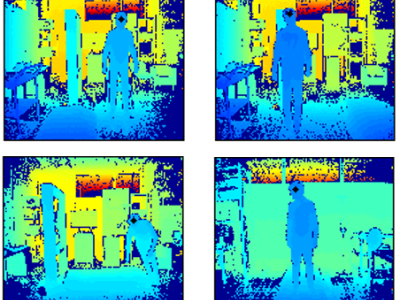
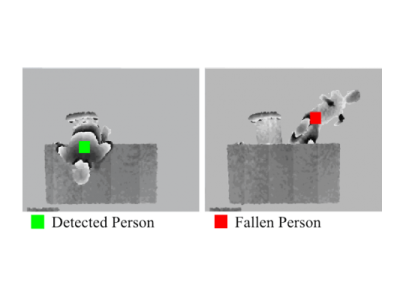
The dataset stores a random sampling distribution with cardinality of support of 4,294,967,296 (i.e., two raised to the power of thirty-two). Specifically, the source generator is fixed as a symmetric-key cryptographic function with 64-bit input and 32-bit output. A total of 17,179,869,184 (i.e., two raised to the power of thirty-four) randomly chosen inputs are used to produce the sampling distribution as the dataset. The integer-valued sampling distribution is formatted as 4,294,967,296 (i.e., two raised to the power of thirty-two) entries, and each entry occupies one byte in storage.
- Categories: