*.zip

This article explores the required amount of time series points from a high-speed computer network to accurately estimate the Hurst exponent. The methodology consists in designing an experiment using estimators that are applied to time series addresses resulting from the capture of high-speed network traffic, followed by addressing the minimum amount of point required to obtain in accurate estimates of the Hurst exponent.
- Categories:
 372 Views
372 Views
Datasets as described in the research paper "Intrusion Detection using Network Traffic Profiling and Machine Learning for IoT Applications".
There are two main dataset provided here, firstly is the data relating to the initial training of the machine learning module for both normal and malicious traffic, these are in binary visulisation format, compresed into the document traffic-dataset.zip.
- Categories:
6034 Views
Files supplement_20-TIE-2530_Matlab.zip and supplement_20-TIE-2530_Modelsim.zip complement the publication under the title "A Direct Modulation for Matrix Converters based on the One–cycle Atomic operation developed in Verilog HDL", which is under review process.
- Categories:
378 Views
本研究中使用的柑橘叶数据集来自 PlantVillage [24],用于以下方面的开放访问公共资源: 与农业有关的内容。数据集包括三种类型柑桔叶片:柑桔健康,柑桔HLB(黄龙病) 一般,柑橘HLB严重。原始数据集包含4577张柑橘叶片图像,分为三部分 分类
- Categories:
1161 Views
This dataset contains the data associated with the electrically equivalent model of the IEEE Low Voltage (LV) test feeder for use of the distribution network studies. This dataset is for the letter entitled:" A Reduced Electrically-Equivalent Model of the IEEE European Low Voltage Test Feeder".
- Categories:
3625 Views
This is the five mainstream stock market indices dataset. It includes XJO, DJI, IXIC, HSI, and N225 indices from Sep. 2010 ~ Aug. 2020.
- Categories:
398 Views
Optical Character Recognition (OCR) system is used to convert the document images, either printed or handwritten, into its electronic counterpart. But dealing with handwritten texts is much more challenging than printed ones due to erratic writing style of the individuals. Problem becomes more severe when the input image is doctor's prescription. Before feeding such image to the OCR engine, the classification of printed and handwritten texts is a necessity as doctor's prescription contains both handwritten and printed texts which are to be processed separately.
- Categories:
24327 Views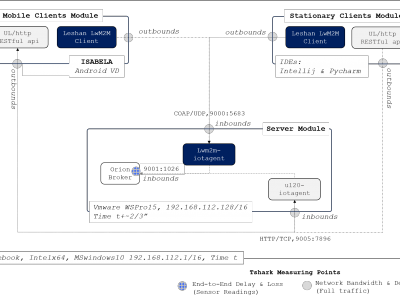
We compared the performances of an LwM2M device management protocol implementation and FIWARE’s Ultralight 2.0. In addition to demonstrating the viability of the proposed approach, the obtained results point to mixed advantages/disadvantages of one protocol over the other.
- Categories:
417 Views
We introduce a new database of voice recordings with the goal of supporting research on vulnerabilities and protection of voice-controlled systems (VCSs). In contrast to prior efforts, the proposed database contains both genuine voice commands and replayed recordings of such commands, collected in realistic VCSs usage scenarios and using modern voice assistant development kits.
- Categories:
1939 Views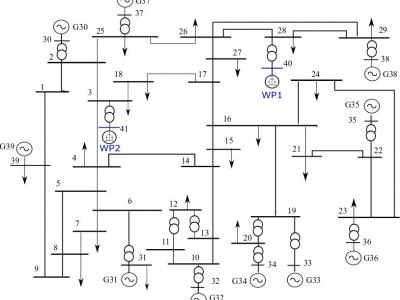
The uploaded data file is a part of data used or generated by a real time security system for frequency control in electrical grids with variable renewable generation proposed in a paper entitled: “Dynamic regulation in electrical networks with non-controlled sources”. The proposed security system analyzes the electrical network in both steady-state and dynamic state. The test systems IEEE 39-bus were used adding wind generation models to evaluate the proposed security system.
- Categories:
692 Views