Sensors
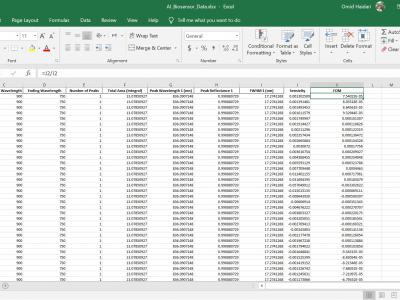
Comprehensive dataset (5000 spectra) of simulated grating biosensor reflections in Excel format. Generated via Lumerical FDTD, it includes 11 parameters (thickness, RI, peak wavelength, FWHM, reflectance, etc.). It is ideal for data visualization, sensor response exploration, and AI/ML benchmarking. The full dataset in Excel format is coming soon! Follow this repository to be notified when it's released. In the meantime, feel free to browse the README for more information about the project.
- Categories:
 320 Views
320 Views
This dataset provides 6D magnetic localization data for surgical instrument tracking, focusing on position and orientation estimation in minimally invasive procedures. It includes various trajectory experiments such as square, circular, saddle-shaped, and helical paths, along with simulated minimally invasive knee surgery and needle sampling experiments. Additionally, it contains dynamic error correction verification data. Data is collected using 16 LIS3MDL magnetometers at 300 Hz, offering both raw and filtered data for algorithm validation.
- Categories:
40 Views
The experiments were conducted at RAICo Lab in West Cumbria. The data were real-time data collected during experiments to validate the CAP system. The underwater robot moves autonomously along three different paths, while the surface robot follows the underwater robot's movement simultaneously. The uploaded file consists of nine data sets. Three experiments were conducted for each trajectory, resulting in a total of nine datasets. The nine subsets are: Lawnmower1-3, Random1-3, and Square1-3.
- Categories:
200 Views
This dataset comprises Channel State Information (CSI) data collected from WiFi signals in six indoor environments, specifically designed for research in indoor intrusion detection. The dataset captures fine-grained variations in wireless signals caused by human, which are indicative of potential intrusions. CSI data, extracted from commercial WiFi chipsets, provides detailed amplitude and phase information across subcarriers, enabling robust detection of subtle environmental changes.
- Categories:
124 Views
This dataset contains the raw data acquired by a wearable, graphene-PbS quantum dot photodetector platform for smart contact lenses under indoor light illumination by a Philips Hue GU10 bulb at colour temperature settings of 2200K, 4000K and 6500K and illuminance of 100 lux. In addition, it also contains S-11 magnitude data acquired on a PocketVNA from near field communication coils designed for wireless power and data transmission for this contact lens platform.
- Categories:
23 Views
One of the leading causes of early health detriment is the increasing levels of air pollution in major cities and eventually in indoor spaces. Monitoring the air quality effectively in closed spaces like educational institutes and hospitals can improve both the health and the life quality of the occupants. In this paper, we propose an efficient Indoor Air Quality (IAQ) monitoring and management system, which uses a combination of cutting-edge technologies to monitor and predict major air pollutants like CO2, PM2.5, TVOCs, and other factors like temperature and humidity.
- Categories:
373 Views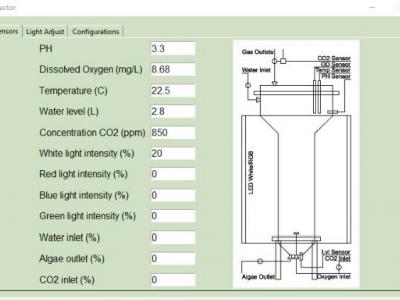
<p>Code used to read the sensors, and light control</p>
- Categories:
101 Views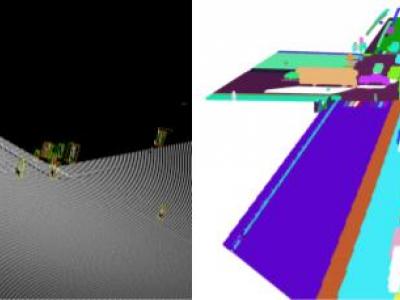
This paper is released with our paper titled “Annotated 3D Point Cloud Dataset for Traffic Management in Simulated Urban Intersections”. This paper proposed a 3D simulation based approach for generating an elevated LiDAR based 3D point cloud dataset simulating traffic in road intersections using Blender. We generated randomized and controlled traffic scenarios of vehicles and pedestrians movement around and within the intersection area, representing various scenarios. The dataset has been annotated to support 3D object detection and instance segmentation tasks.
- Categories:
110 Views
Can we perceive the three-dimensional posture of the whole human body solely from extremely low-resolution thermal images (e.g., $8\times8$-pixels)?
This paper investigates the possibility of this challenging task.
Thermal images capture only the intensity of radiation, making them less likely to contain personal information such as facial or clothing features.
Thermal sensors are commonly integrated into daily-use appliances, such as air conditioners, automatic doors, and elevators.
- Categories:
95 Views
GNSS-R Data for the paper: First Shipborne GNSS-R Ultra-long Observation Utilizing Oceangoing Freighter
- Categories:
33 Views