Machine Learning

130 videos are available, captured in Patras, Greece, displaying drivers in real cars, moving under nighttime conditions where drowsiness detection is more important.The participating drivers are: 11 males and 10 females with different features (hair color, beard, glasses, etc). The videos are split in 2 categories:
- Categories:
 2115 Views
2115 Views
content-based dataset that composes of 12 features for eight common types of files (JPG, PNG, HTML, TXT, MP4, M4A, MOV, and MP3) to be suitable for file type identification (FTI). These features were extracted from pool of file fragment of size 512 byte each from all the prementioned eight types. This dataset is developed in such a way that can be used for supervised and unsupervised ML model. It provides the ability to classifying and clustering the above-mentioned type into two levels.
- Categories:
75 Views
The data of the AC report are collected from the website JUCHAO(http://www.cninfo.com) through the crawler process of Python.
The text feature data is obtained by computing AC reports with the machine learning and text analysis methods of Python.
The data includes 1349 firms from 2014-2019, with 6987 observations.
- Categories:
342 ViewsEarly detection of retinal diseases is one of the most important means of preventing partial or permanent blindness in patients. One of the major stumbling blocks for manual retinal examination is the lack of a sufficient number of qualified medical personnel per capita to diagnose diseases.
- Categories:
6206 Views
The abstract will be written once the manuscript is accepted.
- Categories:
392 Views
Access to potable water is a critical requirement for human survival. Beyond drinking, water is also necessary for animal consumption, irrigation, as well as domestic and commercial uses. Laboratory assessments of water samples to determine their fitness for use is a vital step in water quality assurance processes. However, laboratory assessments require adherence to stringent measures, which might be difficult to comply with.
- Categories:
4195 Views
Printed circuit board (PCB) defect data set. Contains about 400 images with 4 defects (mouse bite, open circuit, short circuit, spur) for image detection, classification and registration tasks.
- Categories:
475 Views
Although several databases of handwriting movements have been created so, none of them has been specifically designed for studying the effect of age during ellipse drawing. Ninety subjects voluntarily participated in the database construction. Their age ranged from 19 to 85 years: 30 participants in the range [19, 39] years, 30 in the range [40, 59] and 30 subjects in the range [60, 85]. Twenty-six women (range 19-72 years) and sixty-four men (range 25-85 years) participated.
- Categories:
242 Views
This paper proposes two new monitoring methods capable of detecting electrical disturbances in low voltage grids. Both approaches rely on machine learning techniques that classify voltage signals in the frequency domain. The first technique here proposed uses the Fourier Transform (FT) of the voltage waveform and classifies the corresponding complex coefficients through a Multilayer neural network with Multi-Valued Neurons (MLMVN). In this case, the structure of the classifier has three layers and a small number of neurons in the hidden layer.
- Categories:
1439 Views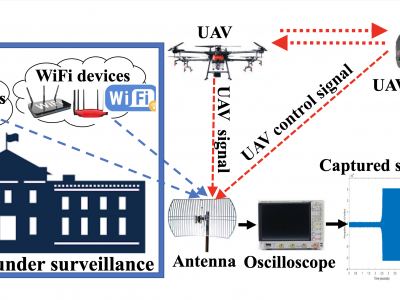
This article presents the details of the Cardinal RF (CardRF) dataset. CardRF is acquired to foster research in RF- based UAV detection and identification or RF fingerprinting. RF signals were collected from UAV controllers, UAV, Bluetooth, and Wi-Fi devices. Signals are collected at both visual line-of-sight and beyond-line-of-sight. The assumptions and procedure for the data acquisition are presented. A detailed explanation of how the data can be utilized is discussed. CardRF is over 65 GB in storage memory.
- Categories:
9846 Views