Image Processing

Forest wildfires are one of the most catastrophic natural disasters, which poses a severe threat to both the ecosystem and human life. Therefore, it is imperative to implement technology to prevent and control forest wildfires. The combination of unmanned aerial vehicles (UAVs) and object detection algorithms provides a quick and accurate method to monitor large-scale forest areas.
- Categories:
 1360 Views
1360 Views
The research data folder contains two primary subfolders, namely the "exper1" and "exper2" folders. These folders hold the experimental data and results relevant to our study.
- Categories:
189 Views
As with most AI methods, a 3D deep neural network needs to be trained to properly interpret its input data. More specifically, training a network for monocular 3D point cloud reconstruction requires a large set of recognized high-quality data which can be challenging to obtain. Hence, this dataset contains the image of a known object alongside its corresponding 3D point cloud representation. To collect a large number of categorized 3D objects, we use the ShapeNetCore (https://shapenet.org) dataset.
- Categories:
680 Views
The dataset exemplifies land vehicle targets, tanks, and comprises 1000 time-frequency representation (TFR) images in jpg format with a resolution of 875x656 pixels. Each image is accompanied by labels containing 14 parameters for geometric parameter prediction.
- Categories:
97 Views
The advancement of machine and deep learning methods in traffic sign detection is critical for improving road safety and developing intelligent transportation systems. However, the scarcity of a comprehensive and publicly available dataset on Indian traffic has been a significant challenge for researchers in this field. To reduce this gap, we introduced the Indian Road Traffic Sign Detection dataset (IRTSD-Datasetv1), which captures real-world images across diverse conditions.
- Categories:
1710 Views
The dataset is generated specifically to simulate the essential components for driving environments in a virtual campus of Chulalongkorn University, including street blocks, various pavements, lane markings, traffic signs, lamp poles, and pedestrians, among other features. We selected this campus for our simulation due to its distinctive road and pavement environments, which are unique to Thailand and other Asian countries. This choice contrasts with many widely cited datasets that predominantly feature environments from European or other regions.
- Categories:
152 Views
Arabic handwritten letters Dataset (AHLD) consists of 8,000 handwritten Arabic letter images of size 128x128 pixels, distributed into 28 classes (Arabic alphabets). This dataset is derived from processing 582 images, each containing several letters,
written by 15 individuals. The dataset creation involves a series of image processing operations: image acquisition, grayscale conversion, binarization, noise reduction, segmentation, normalization, skeletonization, and dataset labeling.
- Categories:
392 Views
Experimental results and analysis demonstrate that the proposed scheme is secure, reliable, easy to implement, and capable of handling binary, grayscale, and color secret images as well as cover images.The characteristics and effectiveness of the proposed algorithm are demonstrated through experiments and comparative analysis. Specifically, we illustrate its application by considering four cover images that share one secret image, implemented using Matlab 2018 programming. The experimental images are shown , and each size is 128´128.
- Categories:
34 Views
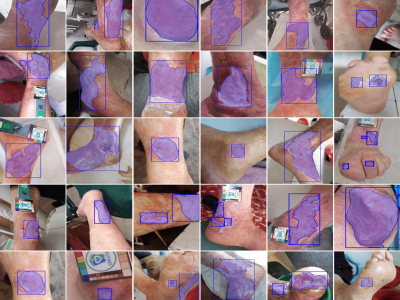
Chronic wounds pose an ongoing health concern globally, largely due to the prevalence of conditions such as diabetes and leprosy's disease. The standard method of monitoring these wounds involves visual inspection by healthcare professionals, a practice that could present challenges for patients in remote areas with inadequate transportation and healthcare infrastructure. This has led to the development of algorithms designed for the analysis and follow-up of wound images, which perform image-processing tasks such as classification, detection, and segmentation.
- Categories:
1263 Views