Geoscience and Remote Sensing

In underground mining process, the evolution of fissures, fractures, and breakages in overlying rock strata can lead to water inrush and many other serious risks including rock bursts, roof collapses, and ground subsidence. Since directly observing strata behavior is challenging, downscaled similar material simulations are often relied upon as a proven effective method for strata pattern analysis.
- Categories:
 118 Views
118 Views
This is a reservoir water surface area and water levels dataset including 32 major reservoirs in Mekong River basin. For all the 32 reservoirs, water levels were inverted by using improved DEM-derived A-E model (combined with actual reservoir parameters limitation), improved DEM-derived A-E model (combined with actual reservoir parameters limitation) or satellite-derived A-E model based on the Landsat-derived surface area. An initial time series was constructed based on the optimal improved A-E model according to their own altimetry data availability.
- Categories:
73 Views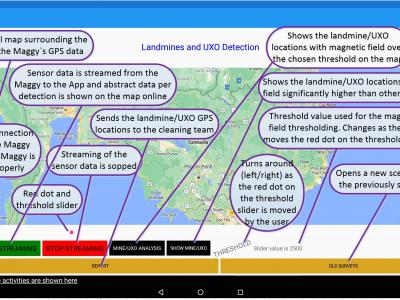
In this research, a small-scale drone with the required magnetometer sensor technologies and novel intelligent automated techniques -- Maggy, was built to automate and ease the procedures of cleaning landmines and UXO/IDE. The dataset with an MP4-formated video demonstrates how a magnetometer-integrated autonomous drone can map the magnetic field of a landmine region effectively and efficiently using an intelligent application through near real-time data streaming.
- Categories:
217 Views
CARLA-AOD is a novel aerial object detection dataset created using the CARLA autonomous driving simulator. It comprises 2,160 images from 18 diverse urban and rural scenarios, featuring 4 vehicle categories, 24 viewpoints, and 5 scales. This dataset aims to support research in aerial object detection, offering comprehensive viewpoint coverage and rich environmental diversity to enhance model performance and generalization.
- Categories:
1017 Views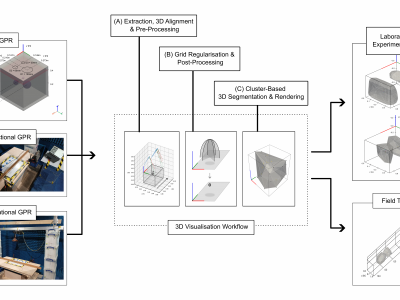
Ground Penetrating Radar (GPR) facilitates the detection and localisation of subsurface structural anomalies in critical transport infrastructure (e.g. tunnels), better informing targeted maintenance strategies. However, conventional fixed-directional systems suffer from limited coverage - especially of less-accessible structural aspects (e.g. crowns) - alongside unclear visual output of anomaly spatial profiles, both for physical and simulated datasets.
- Categories:
536 Views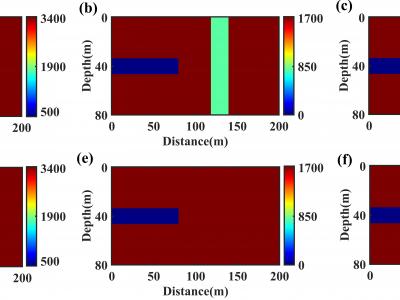
This is a standard two-dimensional model of a tunnel, where the parameters of the tunnel cavity are set to the air medium. Accordingly, the P-wave velocity, S-wave velocity, and density are set to: 340m/s, 0m/s, and 120kg/m3, respectively. The model size is 80 grid points in the vertical direction and 200 grid points in the horizontal direction. The tunnel size is set with a vertical rectangular structure located 40m in front of the tunnel face (at 120m on the X-axis).
- Categories:
317 Views
The detection of the collapse of landslides trigerred by intense natural hazards, such as earthquakes and rainfall, allows rapid response to hazards which turned into disasters. The use of remote sensing imagery is mostly considered to cover wide areas and assess even more rapidly the threats. Yet, since optical images are sensitive to cloud coverage, their use is limited in case of emergency response. The proposed dataset is thus multimodal and targets the early detection of landslides following the disastrous earthquake which occurred in Haiti in 2021.
- Categories:
1011 Views
Forest wildfires are one of the most catastrophic natural disasters, which poses a severe threat to both the ecosystem and human life. Therefore, it is imperative to implement technology to prevent and control forest wildfires. The combination of unmanned aerial vehicles (UAVs) and object detection algorithms provides a quick and accurate method to monitor large-scale forest areas.
- Categories:
1365 Views
The dataset aims to compile images of buildings with structural damage for analysis. The images can be classified by the severity of damage to building facades after seismic events using deep learning techniques, particularly pre-trained convolutional neural networks and transfer learning. The analysis can precisely identify structural damage levels, aiding in effective evaluation and response strategies.
- Categories:
341 Views
The compressed files to be uploaded include three types: tif, csv, and py files.The compressed files to be uploaded include three types: tif, csv, and py files. These documents are directly related to our article.The following is a brief overview of the following files:
tif: 4160 training set images and 40 test set images.
csv: The AGB value corresponding to each image.
py:The code of data augmentation.
We hope that the documents we uploaded can make some contribution to the research of AGB estimation
- Categories:
75 Views