Artificial Intelligence

This is the dataset for paper VI-BEVSEG training and testing. For more details about the dataset structure, please refer to Nuscense or V2X-Sim. We only use the number 1 vehicle in the V2X-Sim dataset. Replace the folder in this dataset, and only keep the vehicle 1 six onboard cameras information, infrastructure camera information and their semantic camera information in 'sweeps' and 'samples' folder. Then replace the 'v1.0-trainval' folder with ours and put the h5 maps under V2X-Sim folder.
- Categories:
 11 Views
11 Views
This is the dataset for paper VI-BEVSEG training and testing. This dataset mostly inherits from V2X-Sim dataset. Follow the same dataset structure as the V2X-Sim dataset. Follow the V2X-Sim instruction to use. The only change we made is adding some 'h5' ground truth semantic maps. And we only keep the vehicle 1 camera information and infrastructure camera information.
- Categories:
2 Views
This dataset presents longitudinal measurements of plant growth characteristics under varying lighting conditions. Collected for 30 individual plants, the data spans multiple time points and includes key variables such as plant fresh weight (g), plant height (mm), plant width (mm), and number of leaves. Each measurement is associated with a specific plant, date (DD/MM/YYYY), experimental group, and a lighting recipe defined by the percentage composition of Red, Green, and Blue light.
- Categories:
12 Views
When artificial intelligence (AI) systems take actions or make decisions, the issue of accountability for the outcomes or decisions made by AI systems comes into question. The rapid advancement of AI technology poses a greater challenge, as current legal and ethical frameworks struggle to keep up with innovation, resulting in a lack of standardization in existing policies that comprehensively address accountability in AI.
- Categories:
18 Views
- Categories:
49 Views
The integration of artificial intelligence (AI) in the teaching of English as a Foreign Language (EFL) is on the rise alongside technological progress. This implementation is founded on various contemporary theories that have become central in academia, particularly regarding non-native speakers. These theories encompass sociocultural approaches, connectivism, and adaptive learning, which work in conjunction with AI’s capacity to tailor learning experiences and enhance language engagement.
- Categories:
43 ViewsThe integration of artificial intelligence (AI) in the teaching of English as a Foreign Language (EFL) is on the rise alongside technological progress. This implementation is founded on various contemporary theories that have become central in academia, particularly regarding non-native speakers. These theories encompass sociocultural approaches, connectivism, and adaptive learning, which work in conjunction with AI’s capacity to tailor learning experiences and enhance language engagement.
- Categories:
19 Views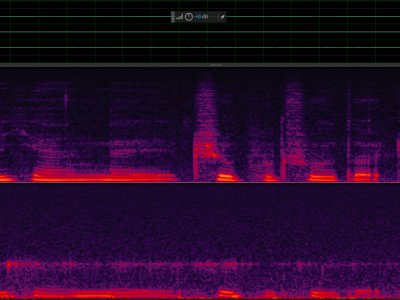
To support research on multimodal speech emotion recognition (SER), we developed a dual-channel emotional speech database featuring synchronized recordings of bone-conducted (BC) and air-conducted (AC) speech. The recordings were conducted in a professionally treated anechoic chamber with 100 gender-balanced volunteers. AC speech was captured via a digital microphone on the left channel, while BC speech was recorded from an in-ear BC microphone on the right channel, both at a 44.1 kHz sampling rate to ensure high-fidelity audio.
- Categories:
30 Views
We created two high-quality point label segmentation datasets, as shown on the left side of Figure 1, WD with a camera magnification of 3 and PLD with a magnification of 40, respectively. The WD is a focal magnification of 3 times, which is a larger field of view consisting of thinner wires, which may be power lines, fiber optic cables, steel wire pulling cables, etc. The PLD is a magnification to a maximum focal length of 40 times, which consists of high-voltage power lines or fiber optic cables with distinctive features.
- Categories:
28 Views
The Lemon Leaf Disease Dataset (LLDD) is a high-quality image dataset designed for training and evaluating machine learning models for lemon leaf disease classification. The dataset contains 9 classes of images of healthy and diseased lemon leaves, such as; Anthracnose. Bacterial Blight, Citrus Canker, Curl Virus, Deficiency Leaf, Dry Leaf, Healthy Leaf, Sooty Mould, Spider Mites, making it suitable for tasks such as plant disease instance segmentation, detection, image classification, and deep learning applications in agriculture.
- Categories:
116 Views