Artificial Intelligence

This dataset comprises a comprehensive collection of educational courses, each characterized by several key attributes: interests, title, description, category, level, past experience, and rating.
- Categories:
 18 Views
18 Views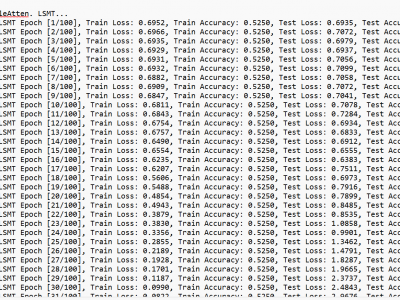
RAN Slicing (RS) is a 6G Radio Access Network technology for resource allocation that meets the diverse needs of users. The current surge in traffic across vertical services requires a paradigm capable of handling unpredictability in a stochastic environment. This paper follows a sequential approach to address the differing needs in RS. We propose an extended application powered by a Double Deep Q Network (DDQN) to instantiate an Apprentice Agent (AA) that serves users based on on-demand requests.
- Categories:
130 Views
The Naval Air Training and Operating Procedures Standardization (NATOPS) manual standardizes general flight and operating procedures for the US naval aircraft. There are a large number of publications that belong to NATOPS; among the many, an aircraft signals manual (NAVAIR 00-80T-113) contains information about all aircraft systems including general aircraft and carrier flight deck handling signals.
- Categories:
13 Views
<p>This meteorological data is provided by the Inner Mongolia Meteorological Bureau and includes data from three stations.
- Categories:
40 Views
<p>This meteorological data is provided by the Inner Mongolia Meteorological Bureau and includes data from three stations.
- Categories:
13 Views
The experimental protocol provided to record for two minutes two IMUs channels assembled on a variable stiffness prosthetic foot (one on the main body of the prosthesis and the other on the ankle), 3-axis linear accelerations (ax , ay and az) and 3-axis Euler angles (θx , θy and θz), at 100 Hz for seven activities (walking, fast walking, stand, stairs and ramps ascending and descending) under different Dx slider configurations (Dx = 42, 45, 48, 51, and 54 mm), i.e. stiffness settings.
- Categories:
129 Views
We present a dataset of histopathology images from OSCC patients treated at Sun Yat-sen Memorial Hospital (2015–2022). Each case includes two tissue sections (core and boundary), with six images per patient captured at ×200, ×400, and ×1000 magnifications (2592×1944 pixels). Key histopathological features—such as cancer cells, nests, keratin pearls, nuclear atypia, and necrosis—are included. The study was approved by the Ethics Committee with a waiver of informed consent, and patient-level diagnosis and prognosis annotations were obtained from electronic records.
- Categories:
14 Views
Artificial Intelligence (AI) has increasingly influenced modern society, recently in particular through significant advancements in Large Language Models (LLMs). However, high computational and storage demands of LLMs still limit their deployment in resource-constrained environments. Knowledge distillation addresses this challenge by training a smaller language model (student) from a larger one (teacher). Previous research has introduced several distillation methods for both generating training data and training the student model.
- Categories:
19 Views
Artificial Intelligence (AI) has increasingly influenced modern society, recently in particular through significant advancements in Large Language Models (LLMs). However, high computational and storage demands of LLMs still limit their deployment in resource-constrained environments. Knowledge distillation addresses this challenge by training a smaller language model (student) from a larger one (teacher). Previous research has introduced several distillation methods for both generating training data and training the student model.
- Categories:
15 Views
Data associated with the article: "PM2.5 Retrieval with Sentinel-5P Data over Europe Exploiting Deep Learning"
- Categories:
23 Views