Artificial Intelligence

Este proyecto se desarrolló para optimizar el análisis de suelos agrícolas en cultivos de papa, con un enfoque en mejorar la precisión y accesibilidad de los diagnósticos de nutrientes esenciales (NPK) a través de tecnología de sensores. En primer lugar, se realizó la calibración de sensores industriales multiparámetro (CWT para NPK y CWT-multiparámetro), basándose en valores de referencia de laboratorios convencionales, lo que permitió configurar un marco de medición confiable.
- Categories:
 212 Views
212 Views
The SINEW 15 Biomarker dataset was extracted from the sensor data collected by a longitudinal study called Sensors IN-home for Elder Wellbeing (SINEW).
- Categories:
18 Views
During gas hydrate extraction, insufficient heating or depressurization can lead to incomplete hydrate decomposition, resulting
in lower-than-expected actual gas production. In this paper, a method for assessing the degree of hydrate decomposition based on an electronic nose
system is proposed. First, the electronic nose system was developed to
collect the information of gas produced by gas hydrate decomposition
under different humidity conditions. Then, a Convolutional Neural
Network combined with Domain Adaptive Compensation feature
- Categories:
10 Views
This dataset presents the capacity fade data for eight Lithium Titanate Oxide (LTO) battery cells over progressive charge-discharge cycles. The measurements, recorded at intervals of 250 cycles up to 3500 cycles, track the aging effects on battery capacity over time. The aging procedure includes a rest period of 10 minutes between charging and discharging cycles. Each charging and discharging process was conducted with a constant current of 1 ampere (A). The maximum charge voltage was set to 2.75 volts (V), while the minimum discharge voltage was set at 1.30 V.
- Categories:
182 Views
IWSLT2017-zh-en;WMT18-zh-en;CoQA
The IWSLT 2017 Multilingual Task addresses text translation, including zero-shot translation, with a single MT system across all directions including English, German, Dutch, Italian and Romanian. As unofficial task, conventional bilingual text translation is offered between English and Arabic, French, Japanese, Chinese, German and Korean.
CoQA is a large-scale dataset for building Conversational Question Answering systems.
- Categories:
17 Views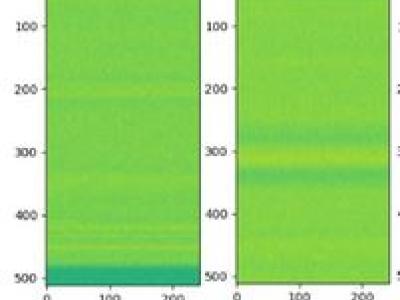
Interference signals degrade and disrupt Global Navigation Satellite System (GNSS) receivers, impacting their localization accuracy. Therefore, they need to be detected, classified, and located to ensure GNSS operation. State-of-the-art techniques employ supervised deep learning to detect and classify potential interference signals. We fuse both modalities only from a single bandwidth-limited low-cost sensor, instead of a fine-grained high-resolution sensor and coarse-grained low-resolution low-cost sensor.
- Categories:
390 Views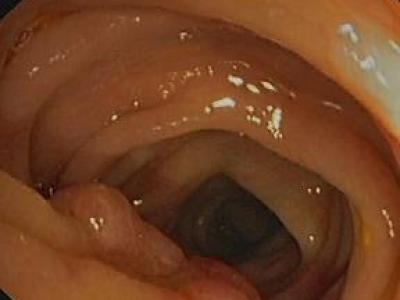
We began by selecting normally exposed images from several prominent endoscopic image repositories, including Kvasir, CVC-ColonDB, CVC-ClinicDB, ETIS-LaribPolypDB, and CVC-300. To simulate exposure anomalies reflective of real-world variations, we utilize the LECARM model, which allows us to apply a random exposure range of (-1,1). This generates a diverse spectrum of exposure anomalies that closely resemble those encountered in clinical settings.
- Categories:
377 Views
This dataset comprises actual measurement data collected from a wind farm located in Xinjiang, China. It includes a range of parameters essential for understanding wind energy potential and environmental conditions. The data features wind speeds recorded at various heights—10 meters, 30 meters, 50 meters, and 70 meters—measured in meters per second (m/s). Additionally, the dataset includes wind direction at these same heights, recorded in degrees (°).
- Categories:
55 Views
We present SMPL-IKS, an inverse kinematic solver to operate on the well-known Skinned Multi-Person Linear model (SMPL) to recover human mesh from 3D skeleton. The challenges of the task are threefold: (1) Shape Mismatching. (2) Error Accumulation. (3) Rotation Ambiguity. Instead of recovering human mesh from costly vertice up-sampling or iterative optimization as in previous methods, SMPL-IKS directly regresses the SMPL parameters (i.e., shape and pose parameters) in a clean and efficient way. Specifically, we propose to infer skeleton-to-mesh via two explicit mappings viz.
- Categories:
61 Views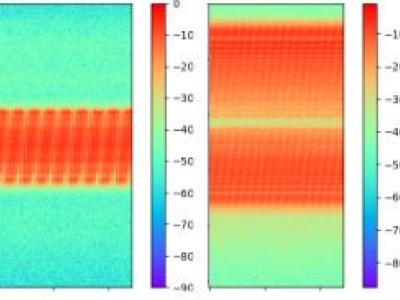
Jamming devices pose a significant threat by disrupting signals from the global navigation satellite system (GNSS), compromising the robustness of accurate positioning. Detecting anomalies in frequency snapshots is crucial to counteract these interferences effectively. The ability to adapt to diverse, unseen interference characteristics is essential for ensuring the reliability of GNSS in real-world applications. We recorded a dataset with our own sensor station at a German highway with eight interference classes and three non-interference classes.
- Categories:
150 Views