Artificial Intelligence

This dataset contains different intestinal polyp datasets, in which the method of dividing test set and training set is the same as that mentioned in most intestinal polyp segmentation methods, where the training set consists of pictures from Kvasir and CVC-ClinicDB, and pictures from the two datasets are mixed into the same training set. The test set clearly indicates the division of the test set from different data sets in the form of folder names, and all images are unified as 352*352.
- Categories:
 195 Views
195 Views


3D Gaussian Splatting performs 3D reconstruction by densifying sparse point clouds into Gaussian ellipsoids of the order of 100,000, and the reconstruction results show excellent visual effects. However, the point cloud data derived from 3D Gaussian Splatting is not fully utilized in the reconstruction process. To this end, this paper proposes to optimize the point cloud data derived from 3D Gaussian Splatting to improve the rendering quality of 3D Gaussian Splatting. First, the sparse point cloud is input into 3D Gaussian Splatting for reconstruction.
- Categories:
517 Views
While deep learning has catalyzed breakthroughs across numerous domains, its broader adoption in clinical settings is inhibited by the costly and time-intensive nature of data acquisition and annotation. To further facilitate medical machine learning, we present an ultrasound dataset of 10,223 Brightness-mode (B-mode) images consisting of sagittal slices of porcine spinal cords (N=25) before and after a contusion injury.
- Categories:
166 Views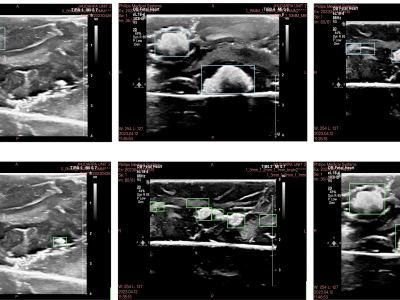
The removal of surgical tools from the brain is a critical aspect of post-operative care. Surgical sponges such as cotton balls are one of the most commonly retained tools, as they become visually indistinguishable from the surrounding brain tissue when soaked with blood and can fragment into smaller pieces. This can lead to life-threatening immunological responses and invasive reoperation, demonstrating the need for new foreign body object detection methods.
- Categories:
144 Views
Modern automotive embedded systems include a large number of electronic control units (ECU) responsible for managing sophisticated systems such as engine control, ABS brake systems, traction control, and power steering systems. To ensure the reliability and effectiveness of these functions, it is essential to apply rigorous test approaches and standards. The integration of diagnostic functions in automotive embedded systems demands consistent tests and a detailed analysis of data.
- Categories:
175 Views
Animal habitat surveys play a critical role in preserving the biodiversity of the land. One of the effective ways to gain insights into animal habitats involves identifying animal footprints, which offers valuable information about species distribution, abundance, and behavior.
- Categories:
296 Views
Data sources of MKG with structured medical knowledge database and unstructured scientific publications
Source Type
Name
Related researches
Structured medical knowledge database
KEGG
[20]
SIDER
[21]
ICD-10
- Categories:
199 Views
The dataset aims to compile images of buildings with structural damage for analysis. The images can be classified by the severity of damage to building facades after seismic events using deep learning techniques, particularly pre-trained convolutional neural networks and transfer learning. The analysis can precisely identify structural damage levels, aiding in effective evaluation and response strategies.
- Categories:
362 Views