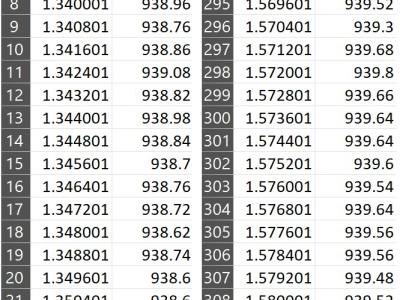
We consider the automation of polishing process for manufactured components, which is typically an iterative, multi-stage process that depends heavily on the practitioner’s expertise and visual inspection to guide decisions on polishing pad changes and fine-tuning of control parameters. We use a model-free, on-policy actor-critic reinforcement learning (RL) algorithm to determine the choice of pad, downforce, rotational speed, polishing duration for each stage, and the total number of polishing / inspection stages.
- Categories: