Artificial Intelligence

LSD4WSD: Learning SAR Dataset for Wet Snow Detection.
The dataset can be found at : https://zenodo.org/record/8111485
- Categories:
 205 Views
205 Views
This Dataset used a non-invasive blood group prediction approach using deep learning. Rapid and meticulous prediction of blood type is a major step during medical emergency before supervising the red blood cell, platelet, and plasma transfusion. Any small mistake during transfer of blood can cause death. In conventional pathological assessment, the blood test is conducted using automated blood analyser; however, it results into time taking process.
- Categories:
3369 Views
This report presents an end-to-end methodology for collecting datasets to recognize handwritten English alphabets in the Indian context by utilizing Inertial Measurement Units (IMUs) and leveraging the diversity present in the Indian writing style. The IMUs are utilized to capture the dynamic movement patterns associated with handwriting, enabling more accurate recognition of alphabets. The Indian context introduces various challenges due to the heterogeneity in writing styles across different regions and languages.
- Categories:
811 Views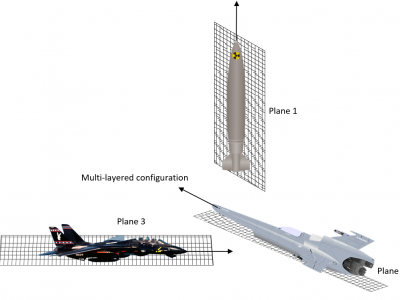
- Categories:
536 Views
Gorakhpur is a city located in the north-eastern region of
Uttar Pradesh state of India. It is a sub-part of Purvanchal
region of Uttar Pradesh and Bihar. In the south-western
part, Gorakhpur periphery spreads along Rapti river. In
the north-western region, Gorakhpur shares its periphery
with Chillua Tal. In the southern part, Ramgarh Tal with a
perimeter of 18 km is located.
Water Bodies:
+ Ramgarh Tal is a historically important heritage site and
is also a tourist attraction; spread over 700 hectares of
- Categories:
337 Views
India is a sub-continent that stretches from Ladakh in
the North to Kanyakumari in the South and from
Gujrat in the West to Arunachal Pradesh, Nagaland
and Manipur in the East. India is currently the
seventh largest country by land covering an area of
approximately 32,87,263 kms.
India's Space Strengths:
India is the fourth country in the world to have
destroyed a satellite of its own. India built the
record-breaking space capability of launching 104
satellites on a single Polar Satellite Launch Vehicle
- Categories:
111 Views
This bearing datasets has high data quality and obvious fault characteristics, so it is a commonly used bearing fault diagnosis standard dataset. In this datasets, three unbalanced datasets under different loads are constructed to testify the recognition effect of the proposed method. The test bench is composed of 2HP (1.5KW) induction motor, fan end bearing, driver end bearing, torque translator and load motor. By using EDM technology, single point faults with different depths were machined on the inner race, outer race and rolling element of the test bearing.
- Categories:
3057 Views
The dataset referenced herein pertains to the robust framework we introduced in our scholarly article titled, "A Graph-Neural-Network-Powered Solver Framework for Graph Optimization Problems." This comprehensive dataset is categorized into three segments: training data, verification data, and test data. Each dataset plays an integral role in the functionality and optimization of the proposed framework. The training data aids in formulating the GNN model, the verification data is used for fine-tuning the model, and the test data assesses the model's performance in test scenarios.
- Categories:
164 Views
Each data instance consists of a paragraph (context), a question, and 4 candidate answers. The goal of each system is to determine the most plausible answer to the question by reading the paragraph.
## Expected Output to Leaderboard
If you intend to submit to the leaderboard [here](https://leaderboard.allenai.org/cosmosqa/submissions/get-started), please follow the data format described on the that page. The prediction file should contain one label per line.
- Categories:
74 Views
Tuberculosis (TB) remains a major global health problem with high incidence and mortality rates worldwide. In recent years, with the rapid development of computer-aided diagnosis (CAD) tools, CAD has played an increasingly important role in supporting tuberculosis diagnosis. However, the development of CAD for TB diagnosis relies heavily on well-annotated computerized tomography (CT) datasets. Unfortunately, the currently available annotations in TB CT datasets are still limited, which hinders the development of CAD tools for TB diagnosis to some extent.
- Categories:
9 Views