Artificial Intelligence

Simultaneously-collected multimodal Mannequin Lying pose (SMaL) dataset is a infant pose dataset based on a posable mannequin. The SMaL dataset contains a set of 300 unique poses under three cover conditions using three sensor modalities: color imaging, depth sensing, and pressure sensing. It represents the first multimodal dataset for infant pose estimation and the first dataset to explore under the cover pose estimation for infants.
- Categories:
 482 Views
482 Views
This is the dataset we collected for the article "Scalable Undersized Dataset RF Classification: Using Convolutional Multistage Training". 17 objects were collected in the laboratory and scanned using a 'cw radar' setup featuring 2x UWB antennas (1 transmit antenna, 1 receive antenna), inside anechoic chamber. There was no clutter added in the experiment.
- Categories:
1364 Views
We uploaded the raw collected fish image data used for model training. These data were divided into those in simple and complex background. In total, there are more than 800 images.
- Categories:
163 Views
This dataset includes real-world Channel Quality Indicator (CQI) values from UEs connected to real commercial LTE networks in Greece. Channel Quality Indicator (CQI) is a metric posted by the UEs to the base station (BS). It is linked with the allocation of the UE’s modulation and coding schemes and ranges from 0 to 15 in values. This is from no to 64 QAM modulation, from zero to 0.93 code rate, from zero to 5.6 bits per symbol, from less than 1.25 to 20.31 SINR (dB) and from zero to 3840 Transport Block Size bits.
- Categories:
1753 Views
This cherry tree disease detection dataset is a multimodal, multi-angle dataset which was constructed for monitoring the growth of cherry trees, including stress analysis and prediction. An orchard of cherry trees is considered in the area of Western Macedonia, where 577 cherry trees were recorded in a full crop season starting from Jul. 2021 to Jul. 2022. The dataset includes a) aerial / Unmanned Aerial Vehicle (UAV) images, b) ground RGB images/photos, and c) ground multispectral images/photos.
- Categories:
2523 Views
This dataset contains bone scan image and its segmentation mask. The segmentation mask is made for the purpose of detecting metastases on bone scan images
- Categories:
708 Views
We create a thermal infrared face dataset (TIF) for fever screening. TIF is collected at the entrance of our university’s engineering building. The infrared face images are captured by an infrared camera under different environmental conditions.
- Categories:
904 Views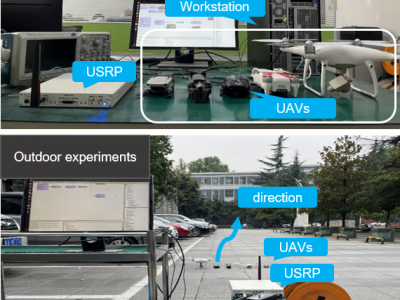
This dataset is about UAV signals.
Both indoor and outdoor experiments are conducted.
- Categories:
805 Views
the summary datasets in aspect-based sentiment analysis task cotain many social reviews.
- Categories:
1233 Views
Description
Forest environmental sound classification is one use case of ESC which has been widely experimenting to identify illegal activities inside a forest. With the unavailability of public datasets specific to forest sounds, there is a requirement for a benchmark forest environment sound dataset. With this motivation, the FSC22 was created as a public benchmark dataset, using the audio samples collected from FreeSound org.
- Categories:
1137 Views