Signal Processing

This MATLAB script demonstrates an approach to beamforming and interference suppression in scenarios with multiple users and multiple interferers. It constructs an N-element linear array, computes beamformer weights through a generalized eigen-decomposition of summed desired and interference correlation matrices, and then runs a Monte Carlo simulation to estimate the Signal-to-Interference-plus-Noise Ratio (SINR) for one of the users under random channel conditions.
- Categories:
 193 Views
193 Views
The data is the obtained using the autotracker application of the 'Tracker' software. The data is time versus x-y coordinates of a marked particle subject to movement in presence of E X B drift. This data can be directly used to calculate the charge-to-mass ratio and electrophoretic mobility of the particle of interest.
- Categories:
39 Views
This paper presents a novel method for non-invasive, cost-effective, and convenient dengue (DNG) detection through smartphone-captured fingertip videos. The proposed method has utilized the ubiquitous technology of smartphones, specifically the camera and built-in light source, to capture photoplethysmog-raphy (PPG) signals for identifying DNG. This contrasts sharply with traditional needle-based methods.
- Categories:
136 Views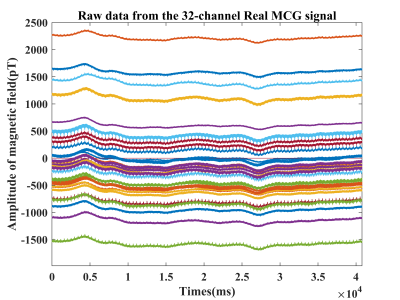
Cardiac functional imaging plays a crucial role in the detection, diagnosis, and prognosis of major cardiac diseases. Magnetocardiography (MCG) provides the benefits of non-invasive measurement and precise reflection of signals generated by the heart’s contraction and relaxation, and is gaining prominence in medical technology. However, due to various reasons, the reviewed dataset was not available and no standard dataset has been published on this topic.
- Categories:
238 Views
A high-quality dataset is essential for validating the effectiveness and accuracy of the proposed compression method. To assess the feasibility of the research methodology, we collected neural signals from 96 channels recorded from two non-human primates using the Blackrock Microsystems system and the Blackrock Cerebus, with a sampling rate of 30 kHz.
- Categories:
36 Views
Walking-friendly cities not only promote health and environmental benefits but also play crucial roles in urban development and local economic revitalization. Generally, pedestrian interviews and surveys used to evaluate walkability, but this is expensive and lack professional insight. To address limitations in current methods for evaluating pedestrian pathways, we propose a novel approach utilizing wearable sensors and deep learning.
- Categories:
99 Views
A multimodal dataset is presented for the cognitive fatigue assessment of physiological minimally invasive sensory data of Electrocardiography (ECG) and Electrodermal Activity (EDA) and self-reporting scores of cognitive fatigue during HRI. Data were collected from 16 non-STEM participants, up to three visits each, during which the subjects interacted with a robot to prepare a meal and get ready for work. For some of the visits, a well-established cognitive test was used to induce cognitive fatigue.
- Categories:
151 Views
In this article, a novel method for interferometric target detection that employs coherent echoes and spatial frequency sampling is proposed. Originating from radio astronomy, interferometric passive microwave imaging has become widely applied for the passive microwave remote sensing of Earth. The proposed technique, termed Interferometric Coherent Echo Detection, is a novel active imaging method that capitalizes on coherent echoes to sample the spatial frequency domain.
- Categories:
24 Views
This is a dataset: a database of radar cross sections of models; The characteristics of the data set include radar frequency, polarization mode (currently only the co-polarized VV and HH), radar Angle of sight (pitch and azimuth), and target characteristics RCS. According to these input feature information, the highly nonlinear feature rcs of the predicted target is estimated. Prediction is actually an interpolation method, which can be divided into two kinds, interpolation and extrapolation. We can try different methods according to the data set provided, please show your skills!
- Categories:
27 Views
Two publicly available datasets, the PASS and EmpaticaE4Stress databases, were utilised in this study. They were chosen because they both used the same Empatica E4 device, which allowed the acquisition of a variety of signals, including PPG and EDA. The dataset consists of in 1587 30-second PPG segments. Each segment has been filtered and normalized using a 0.9–5 Hz band-pass and min-max normalization scheme.
- Categories:
182 Views