Signal Processing

The dataset contains the focus metrics values of a comprehensive synthetic underwater image dataset (https://data.mendeley.com/datasets/2mcwfc5dvs/1). The image dataset has 100 ground-truth images and 15,000 synthetic underwater images generated by considering a comprehensive set of effects of underwater environment. The current dataset focus on the focus metrics of these 15,100 images.
- Categories:
 158 Views
158 Views
Wild-SHARD presents a novel Human Activity Recognition (HAR) dataset collected in an uncontrolled, real-world (wild) environment to address the limitations of existing datasets, which often need more non-simulated data. Our dataset comprises a time series of Activities of Daily Living (ADLs) captured using multiple smartphone models such as Samsung Galaxy F62, Samsung Galaxy A30s, Poco X2, One Plus 9 Pro and many more. These devices enhance data variability and robustness with their varied sensor manufacturers.
- Categories:
491 Views
Hand contact data, reflecting the intricate behaviours of human hands during object operation, exhibits significant potential for analysing hand operation patterns to guide the design of hand-related sensors and robots, and predicting object properties. However, these potential applications are hindered by the constraints of low resolution and incomplete capture of the hand contact data.
- Categories:
204 Views
The synthetic data is generated loosely following the concepts developed by Skomedal and Deceglie (2020)
- Categories:
231 Views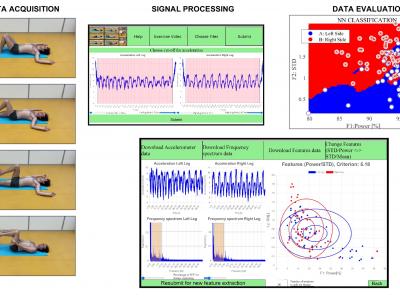
Individual physiotherapy is a significant part of the treatment for patients experiencing various forms of pain and health issues. Recent research shows rehabilitation as an important part of therapy for those with abdominal wall defects. It also plays a crucial role in chest surgery, by helping optimize preoperative assessments and postoperative rehabilitation strategies essential for successful surgery outcomes. With recent technological advancements, new tools have become available to healthcare professionals.
- Categories:
20 Views
To develop radio frequency-based drone recognition, we release an RF spectrogram dataset, named DroneRFb-Spectra. All signals of drones were collected by a Universal Software Radio Peripheral (USRP) device, recording three Industrial Scientific Medical (ISM) bands under urban scenarios. The classes cover 7 common brands, i.e., DJI, Vbar, FrSky, Futaba, Taranis, RadioLink, and Skydroid, with a total number of 14460. Each spectrogram has been downsampled to the size of 512x512 from the original IQ data with a length of 50ms by using the short-time Fourier transform.
- Categories:
856 Views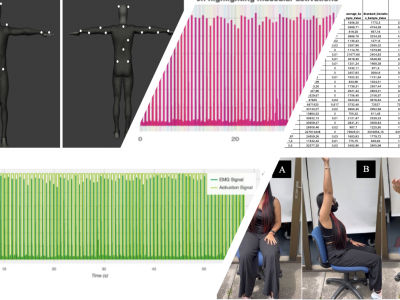
A database was created in .XLSX and .CSV formats containing the processing of an EMG signal and the position and angle error during the execution of three dynamic tasks based on the three-dimensional movement of the upper limb. This data was recorded from the quantification of the hand position error.
- Categories:
514 Views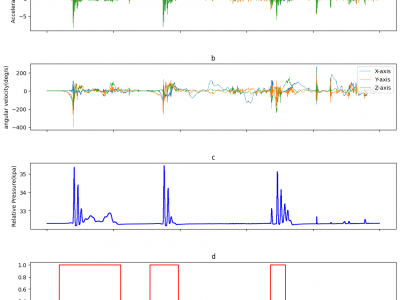
The data was collected by outfitting one of the players with the experimental balloon, which incorporated the embedded circuit and sensors. The sensors positioned at the top-right to the player within the bubble balloon, where a player stand inside. The sensors' data were collected at specific sampling frequencies (Accelerometer: 1000Hz, Gyroscope: 1000Hz, and Pressure: 40Hz). The experiment was conducted involving five different players. This approach allowed for the inclusion of diverse data samples, taking into account variations in player metrics, movements, and gameplay dynamics.
- Categories:
178 Views
Developing mind-controlled prosthetics that seamlessly integrate with the human nervous system is a significant challenge in the field of bioengineering. This project investigates the use of labelled brainwave patterns to control a bionic arm equipped with a sense of touch. The core objective is to establish a communication channel between the brain and the artificial limb, enabling intuitive and natural control while incorporating sensory feedback.
The project involves:
- Categories:
552 Views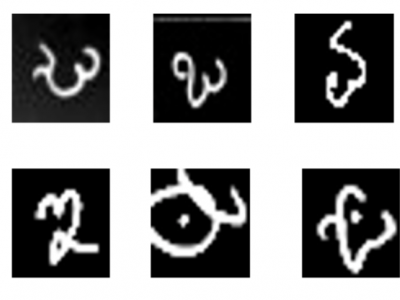
One of the Dravidian language spoken majorly by 60 million people in and around Karnataka state of India is known as Kannada. It is one among 22 scheduled languages of India. Kannada langauge is written in Kannada scriptwhich has its traces back from kadamba script (325-550 AD). There are many languages which were used centuries back and aren’t being used currently whereas Kannada is one such language which is used even today for writing official documents and are being taught at schools which means it is going to be for many years.
- Categories:
172 Views