Signal Processing
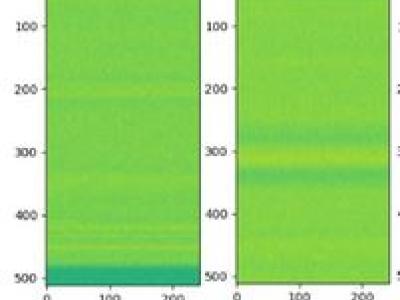
Interference signals degrade and disrupt Global Navigation Satellite System (GNSS) receivers, impacting their localization accuracy. Therefore, they need to be detected, classified, and located to ensure GNSS operation. State-of-the-art techniques employ supervised deep learning to detect and classify potential interference signals. We fuse both modalities only from a single bandwidth-limited low-cost sensor, instead of a fine-grained high-resolution sensor and coarse-grained low-resolution low-cost sensor.
- Categories:
 449 Views
449 Views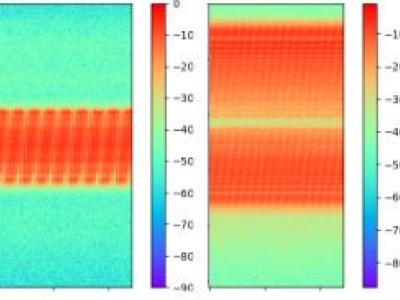
Jamming devices pose a significant threat by disrupting signals from the global navigation satellite system (GNSS), compromising the robustness of accurate positioning. Detecting anomalies in frequency snapshots is crucial to counteract these interferences effectively. The ability to adapt to diverse, unseen interference characteristics is essential for ensuring the reliability of GNSS in real-world applications. We recorded a dataset with our own sensor station at a German highway with eight interference classes and three non-interference classes.
- Categories:
208 Views
Production quality control is an issue of great importance in the industry. Generating defective products leads to wasted time and money. For this reason, we have attempted to develop a production control system using computational artificial intelligence methods. The system, in its current version, has been developed and tested, using the example of controlling the operation of an injection moulding machine producing plastic elements.
- Categories:
176 Views
Multimodal sensor fusion has been widely adopted in constructing scene understanding, perception, and planning for intelligent robotic systems. One of the critical tasks in this field is geospatial tracking, i.e., constantly detecting and locating objects moving across a scene. Successful development of multimodal sensor fusion tracking algorithms relies on large multimodal datasets where common modalities exist and are time-aligned, and such datasets are not readily available.
- Categories:
728 Views
This dataset originates from a longitudinal study examining the factors contributing to the progression of cardiovascular disease. P This particular research employs the unprocessed sequential actigraph recordings collected from an actigraph device. We evaluate sleep quality based on the two indicators as proposed in our previous study [3] which are weekly sleep quality ‘SleepQualWeek’, and sleep consistency ‘SleepCons’. SleepQualWeek and SleepCons are calculated using the pre-processed attribute set derived from the MESA dataset.
- Categories:
240 Views
The breath rate (BR), heart rate (HR), breathing-breathing interval (BBI) and heart rate variability (HRV) are the critical vital sign parameters. In this article, a novel method named adaptive separation variational mode extraction algorithm (ASVME) is proposed to accurately monitor multi-variable vital signs (MVVS) at the same time with a frequency-modulated continuous wave (FMCW) radar system in practical scenarios.
- Categories:
138 Views
The breath rate (BR), heart rate (HR), breathing-breathing interval (BBI) and heart rate variability (HRV) are the critical vital sign parameters. In this article, a novel method named adaptive separation variational mode extraction algorithm (ASVME) is proposed to accurately monitor multi-variable vital signs (MVVS) at the same time with a frequency-modulated continuous wave (FMCW) radar system in practical scenarios.
- Categories:
50 Views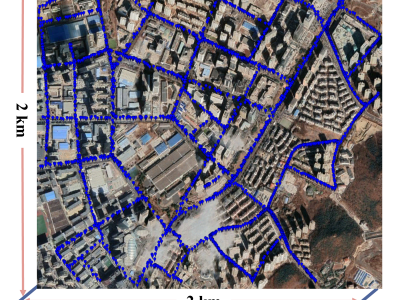
The dataset was collected in the actual outdoor environment of Dalian, China, with specific areas carefully selected to encompass a diverse range of environmental characteristics. These environments are extensive, including not only the urban center with high-rise office buildings and high population density but also suburban areas with scattered low-rise buildings and relative tranquility; additionally, they encompass major urban arteries with constant traffic flow and urban side streets with lighter traffic.
- Categories:
395 Views
Deadbands are embedded functions of transducers frequently exploited to remove false alarms. In existing literature, there are two major methods to design alarm deadbands, either based on the estimated probability density function (PDF) of process variables or the estimated PDF of maximum amplitude deviations (MADs). The former method only applies to independently and identically distributed (IID) process variables, while the latter method does not have this restriction. A natural question is: which method should be used for IID process variables?
- Categories:
66 Views
In the domain of gait recognition, the scarcity of non-simulated, real-world data significantly hampers the performance and applicability of recognition systems. To address this limitation, we present a comprehensive gait recognition dataset - GaitMotion- collected using built-in sensors of Android smartphones in an uncontrolled, real-world environment. This dataset captures the walking activity of 24 subjects (14 females and 10 males) above 18 years old and weighing at least 50 kg.
- Categories:
314 Views