Artificial Intelligence

This LoRa-RFFI project builds a LoRa radio frequency fingerprint identification (RFFI) system based on deep learning techniques. The RF signals are collected from 60 commercial-off-the-shelf LoRa devices. The packet preamble part and device labels are provided. The dataset consists of 19 sub-datasets and please refer to the README document for more detailed collection settings for all the sub-datasets.
- Categories:
 8996 Views
8996 Views
ATTENTION: THIS DATASET DOES NOT HOST ANY SOURCE VIDEOS. WE PROVIDE ONLY HIDDEN FEATURES GENERATED BY PRE-TRAINED DEEP MODELS AS DATA
- Categories:
7265 Views
Re-curated Breast Imaging Subset DDSM Dataset (RBIS-DDSM) is a curated version of 849 images from the CBIS-DDSM dataset available online with a permissive copyright license (CC-BY-SA 3.0). The CBIS-DDSM dataset is an improved version of the DDSM dataset. The authors of the CBIS-DDSM dataset attempted to improve the ground truth by applying simple image processing based methods to enhance the edges without any manual intervention from medical experts in order to segment and annotate masses. However, these annotations (segmentation maps) are inaccurate in most of the images.
- Categories:
976 Views
Object detection via images has advanced quickly over the last few decades, their detection accuracy, categorization, and localization are not consistent. Achieving fast and accurate detection of fashion products in the e-commerce environment is very important for selecting the right category. This is closely related to customer satisfaction and happiness which is a critical aspect.
- Categories:
890 Views
The raw dataset is for the survival analysis of COVID19.
The analyzed data are extracted from this dataset.
- Categories:
385 Views
Study of mind and nature of intelligence is widely studied in cognitive science. Also, Artificial Wisdom which redefines the Artificial Wisdom is emerging research area where machine intelligence must collaborates with the constructive behavior and values of humanity. Thinking ability of human beings is recognized as the consciousness. Researchers from different domains like Cognitive Science, Artificial Intelligence, Psychology, Computer Engineering etc. are used to perform experimentations on consciousness or arousal of thoughts.
- Categories:
302 Views
Abstract—Network slicing (NwS) is one of the main technologies
in the h-generation of mobile communication and
beyond (5G+). One of the important challenges in the NwS
is information uncertainty which mainly involves demand
and channel state information (CSI). Demand uncertainty is
divided into three types: number of users requests, amount
of bandwidth, and requested virtual network functions workloads.
Moreover, the CSI uncertainty is modeled by three
methods: worst-case, probabilistic, and hybrid. In this paper,
- Categories:
1728 Views
These datasets are used for epidemilogical modeling using artifical neural network.
- Categories:
834 Views
# RSS data from smartwatch for Contact Tracing
This dataset was collected for the purpose to understand the proximity between any two smartwatches worn by human.
We used the Google's Wear OS based smartwatch, powered by a Qualcomm Snapdragon Wear 3100 processor, from Fossil sport to collect the data.
The smartwatch is powered by a Qualcomm Snapdragon Wear 3100 processor and has an internal memory of up to 1GB.
Two volunteers were required to wear the smartwatch on different hand and stand at a certain distance from each other.
- Categories:
731 Views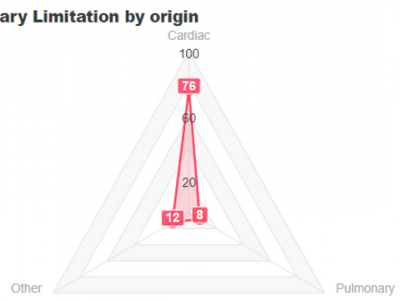
This dataset is the Cardiopulmonary Exercise Test(CPET) processed before using machine learning algorithms. The CPET cases went to a diverse feature engineering process that gives over 100 features and 4 labels. The labels are in binary and define if the patient has one of the following conditions, healthy, primary cardiac, pulmonary or other limitation.
- Categories:
1050 Views