Machine Learning

The detection of the collapse of landslides trigerred by intense natural hazards, such as earthquakes and rainfall, allows rapid response to hazards which turned into disasters. The use of remote sensing imagery is mostly considered to cover wide areas and assess even more rapidly the threats. Yet, since optical images are sensitive to cloud coverage, their use is limited in case of emergency response. The proposed dataset is thus multimodal and targets the early detection of landslides following the disastrous earthquake which occurred in Haiti in 2021.
- Categories:
 765 Views
765 Views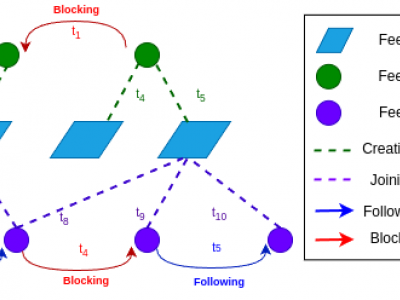
Decentralized social media platforms like Bluesky Social (Bluesky) have made it possible to publicly disclose some user behaviors with millisecond-level precision. Embracing Bluesky's principles of open-source and open-data, we present the first collection of the temporal dynamics of user-driven social interactions. BlueTempNet integrates multiple types of networks into a single multi-network, including user-to-user interactions (following and blocking users) and user-to-community interactions (creating and joining communities).
- Categories:
1008 Views
Machine learning (ML) in the medical domain faces challenges due to limited high-quality data. This study addresses the scarcity of echocardiography images (echoCG) by generating synthetic data using state-of-the-art generative models. We evaluated a cycle-consistent generative adversarial network (CycleGAN), contrastive unpaired translation (CUT) method, and latent diffusion model (Stable Diffusion 1.5).
- Categories:
150 Views
A dataset related to a cable under anomalies conditions while a transmitter (AWG) sends a binary PAM signal to a receiver. The signals are acquired by an oscilloscope. The anomalies were manually forced on the cable under test: air-exposed, water-exposed conductors, and tapping. In the dataset, the signals are also available for normal cable.
- Categories:
381 Views
We are pleased to introduce the Qilin Watermelon Dataset, a unique collection of data aimed at investigating the relationship between a watermelon's appearance, tapping sound, and sweetness. This dataset is the result of our dedicated efforts to capture and record various aspects of Qilin watermelons, a special variety known for its exceptional taste and quality.
- Categories:
1550 Views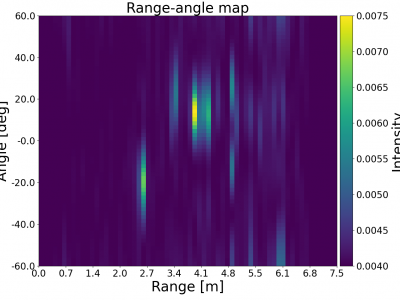
In our work, we propose an innovative system to accurately infer and track occluded target locations using mmWave beat frequency signals. Our approach combines a classic direction-finding method with advanced deep learning techniques, specifically a convolutional neural network (CNN), to enhance detection capabilities. The dataset includes raw beat frequency signal data from the TI IWR6843ISK rev B with TI mmWAVEICBOOST and the TI DCA1000EVM capture board. Corresponding ground truth data (target position) from the Realsense L515 RGB-D camera is also provided.
- Categories:
343 Views
As with most AI methods, a 3D deep neural network needs to be trained to properly interpret its input data. More specifically, training a network for monocular 3D point cloud reconstruction requires a large set of recognized high-quality data which can be challenging to obtain. Hence, this dataset contains the image of a known object alongside its corresponding 3D point cloud representation. To collect a large number of categorized 3D objects, we use the ShapeNetCore (https://shapenet.org) dataset.
- Categories:
637 Views
The dataset exemplifies land vehicle targets, tanks, and comprises 1000 time-frequency representation (TFR) images in jpg format with a resolution of 875x656 pixels. Each image is accompanied by labels containing 14 parameters for geometric parameter prediction.
- Categories:
73 Views
The advancement of machine and deep learning methods in traffic sign detection is critical for improving road safety and developing intelligent transportation systems. However, the scarcity of a comprehensive and publicly available dataset on Indian traffic has been a significant challenge for researchers in this field. To reduce this gap, we introduced the Indian Road Traffic Sign Detection dataset (IRTSD-Datasetv1), which captures real-world images across diverse conditions.
- Categories:
939 Views
The dataset is built upon a multi-layer multi-domain (MLMD) network topology of a real testbed.
- Categories:
381 Views