*.csv (zip)
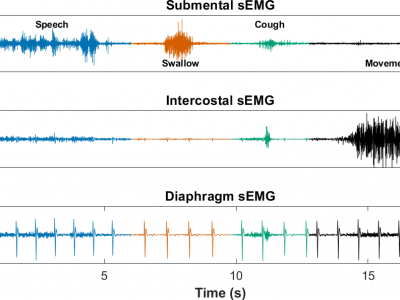
This dataset is associated with an IEEE journal submission titled: "Prediction of larynx function using multichannel surface EMG classification" by the associated authors. The dataset consists of surface electromyography (sEMG) signals recorded from 10 study participants (5 control, 5 laryngectomees), each undertaking 3 recording sessions.
During each session the following were recorded:
- Categories:
 1223 Views
1223 Views
Route planning also known as pathfinding is one of the key elements in logistics, mobile robotics and other applications, where engineers face many conflicting objectives. However, most of the current route planning algorithms consider only up to three objectives. In this paper, we propose a scalable many-objective benchmark problem covering most of the important features for routing applications based on real-world data. We define five objective functions representing distance, traveling time, delays caused by accidents, and two route specific features such as curvature and elevation.
- Categories:
291 Views
The dataset consists of echo data collected at the Matre research station (61°N) of the Institute of Marine Research (IMR), Norway. Six square sea cages (12 × 12 m and 15 m depth; approximately 2000 m^3) were used. The fish's vertical distribution and density were observed continuously by a PC-based echo integration system (CageEye MK IV, software version 1.1.1., CageEye AS, Steinkjer, Norway) connected to an upward facing transducer which multiplexes between 50 kHz (42° acoustic beam angle) and 200 kHz (14° beam angle).
- Categories:
702 Views
Abstract
- Categories:
1032 Views
Radio-frequency noise mapping data collected from Downtown, Back Bay and North End neighborhoods within Boston, MA, USA in 2018 and 2019.
- Categories:
263 Views
The diversity of video delivery pipeline poses a grand challenge to the evaluation of adaptive bitrate (ABR) streaming algorithms and objective quality-of-experience (QoE) models.
Here we introduce so-far the largest subject-rated database of its kind, namely WaterlooSQoE-IV, consisting of 1350 adaptive streaming videos created from diverse source contents, video encoders, network traces, ABR algorithms, and viewing devices.
We collect human opinions for each video with a series of carefully designed subjective experiments.
- Categories:
2921 Views
This dataset includes PV power production measured on the SolarTech Lab, Politecnico di Milano, Italy. Data are freely available for scientific research purpose and further data validation.
In particular, the dataset is composed of the following variables and specifics, with a time resolution of 1 minute:
- Categories:
6398 Views
To download the dataset click the link provided. To unzip the file, double-click the zipped folder to open it. Then, drag or copy the item from the zipped folder to a new location.
- Categories:
84 Views
We propose a driver pattern dataset consists of 51 features extracted from CAN (Controller Area Network) of Hyundai YF Sonata while four drivers drove city roads of Seoul, Republic of Korea. Under the belief that different driving patterns implicitly exist at CAN data, we collected CAN diagnosis data from four drivers in pursuit of research on driver identification, driver profiling, and abnormal driving behavior detection. Four drivers are named A, B, C, and D.
- Categories:
2601 Views
This dataset represents the main different unique learning behaviors that may be found in any group of learners in e-learning/educational systems. It represents 20 learners through 17 OERs.
- Categories:
1987 Views