
This ZIP file contains two distinct datasets collected over a 13, 14 and 15-day periods.
- Categories:
This ZIP file contains two distinct datasets collected over a 13, 14 and 15-day periods.

The Japan region is characterized by intense seismic activity. This catalog consists of earthquakes in a polygon bounded by 129°27'-144°73' E and 26°96'-43°04' N and from March 6, 2003, to July 10, 2023, obtained from the Japanese Meteorological Agency [1,2]. Aftershocks were identified using Molchan–Dmitrieva’s algorithm [3], which relies on the statistical analysis of the spatiotemporal distribution of seismic events. The aftershocks were subsequently marked using the program described in [4], which is an adaptation of the earlier program developed by Smirnov [5].
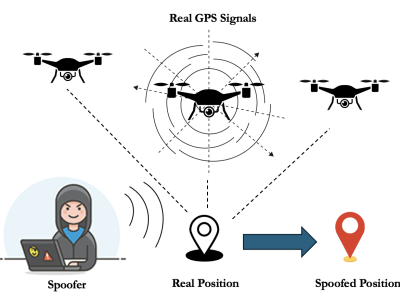
The Drone Sensor Fusion Dataset features high-quality telemetry data from real and attack-modeled UAV flights, leveraging the PX4 flight log dataset. This includes normal flight data prepared for machine learning model training and simulated attack data generated using the 'Coordinated Sensor Manipulation Attack' (CSMA) model. CSMA simulates advanced threats by subtly altering GPS and IMU data to induce undetectable navigation drift.
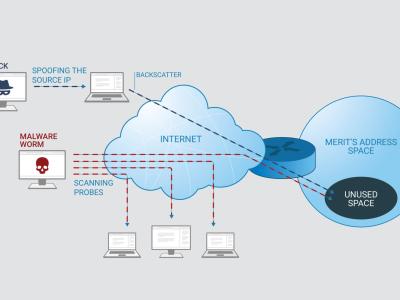
Network telescopes collect and record unsolicited Internet-wide traffic destined to a routed but unused address space usually referred to as “Darknet” or “blackhole” address space. Among the largest network telescopes in the US, Merit Network operates one that receives unsolicited internet traffic on around 475k unused IP addresses. On an average day, the network telescope receives approximately 41.5k packets per second and around 17M bits per second. Description of the attached dataset:
1. Data Source:

To provide a standardized approach for testing and benchmarking secure evaluation of transformer-based models, we developed the iDASH24 Homomorphic Encryption track dataset. This dataset is centered on protein sequence classification as the benchmark task. It includes a neural network model with a transformer architecture and a sample dataset, both used to build and evaluate secure evaluation strategies.

Health degradation issues in automotive power electronics converter systems (PECs) arise due to repetitive thermomechanical stress experienced during real-world vehicle operation. This stress, caused by heat generated during semiconductor operation within PECs, leads to the degradation of semiconductor's operating life. Estimating the power semiconductor junction temperature (Tj) is crucial for assessing semiconductor degradation in operation. Although physics-of-failure-based models can estimate Tj, they require substantial computational power.
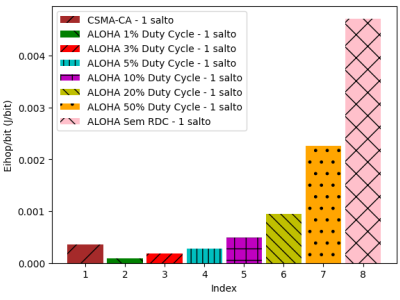
Database of the times the device remained in each state (idle, low power mode, transmitting and listening, respectively), number of hops, hop distance (d), transmission rate (_R) and size of the packet sent (_Nb), measured on the Tmote Sky device using an Aloha Puro protocol with RDC implemented in the Contiki operating system.

Data were collected through the Twitter API, focusing on specific vocabulary related to wildfires, hashtags commonly used during the Tubbs Fire, and terms and hashtags related to mental health, well-being, and physical symptoms associated with smoke and wildfire exposure. We focused exclusively on the period from October 8 to October 31, aligning precisely with the duration of the Tubbs Fire. The final dataset available for analysis consists of 90,759 tweets.
The dataset tracks the performance of eight stock market indices, from six countries. The indices are: IPC, S\&P 500, DAX, DJIA, FTSE, N225, NDX, and CAC. The time period is from the 1st of June 2006 to the 31st of May 2023.The index and the FX data are sourced from Yahoo Finance, and the rest of the variables are retrieved from the OECD.

Gas monitoring plays a crucial role in our intelligent societies. Thus we build those stepwise-collected data for gas concentration modeling in dynamic setting which can boost training data collection. First column is time, you have 8 columns for different sensors, including GM402B, GM702B, GM512B, GM302B, MICS5914, MICS5914, MICS4514, and MICS4514. The remaining 3 columns is recorded as the flow rate, which the flow rate of methane and the oxygen-nitrogen mixture is read as L/min, while hydrogen is read as mL/min.