Security

The processing of this dataset involves the following steps. First, create a list of file paths that includes the paths of 10 binary files. Then, traverse the files one by one, check if each file exists, and if it does, read the file content.
- Categories:
 10 Views
10 Views
We constructed the largest NAS package dataset to date, consisting of 1,489 NAS packages from major third-party sources, which can offer representative data for further research. Given that Synology and QNAP have the largest user bases, these platforms experience the highest frequency of attacks. Furthermore, the NAS package ecosystems provided by other vendors are considerably smaller. So our security measurements focus solely on the NAS packages of Synology and QNAP.
- Categories:
29 Views
<p class="MsoNormal"><span style="mso-spacerun: 'yes'; font-family: 宋体; mso-ascii-font-family: Calibri; mso-hansi-font-family: Calibri; mso-bidi-font-family: 'Times New Roman'; font-size: 10.5000pt; mso-font-kerning: 1.0000pt;"><span style="font-family: Calibri;">This dataset contains expert evaluations of various text features using Grey Relational Analysis (GRA), comparing the performance of original and new prompt words.
- Categories:
22 Views
Cloud computing has become a relatively new paradigm for the delivery of compute re-
sources, with key management services (KMS) playing a crucial role in securely handling cryptographic
operations in the cloud. This paper presents the microbenchmark of cloud cryptographic workloads, in-
cluding SHA HMAC generation, AES encryption/decryption, ECC signature/verification, and RSA encryp-
tion/decryption, across Function-as-a-Service (FaaS) and Infrastructure-as-a-Service (IaaS) in conjunction
- Categories:
69 Views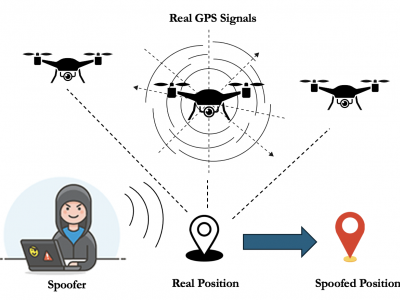
The Drone Sensor Fusion Dataset features high-quality telemetry data from real and attack-modeled UAV flights, leveraging the PX4 flight log dataset. This includes normal flight data prepared for machine learning model training and simulated attack data generated using the 'Coordinated Sensor Manipulation Attack' (CSMA) model. CSMA simulates advanced threats by subtly altering GPS and IMU data to induce undetectable navigation drift.
- Categories:
542 Views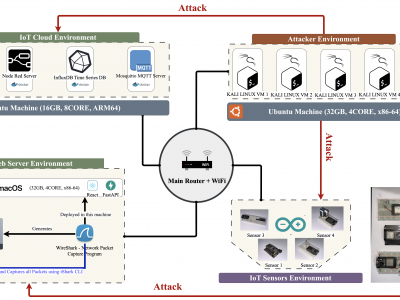
This paper presents an enhanced methodology for network anomaly detection in Industrial IoT (IIoT) systems using advanced data aggregation and Mutual Information (MI)-based feature selection. The focus is on transforming raw network traffic into meaningful, aggregated forms that capture crucial temporal and statistical patterns. A refined set of 150 features including unique IP counts, TCP acknowledgment patterns, and ICMP sequence ratios was identified using MI to enhance detection accuracy.
- Categories:
523 Views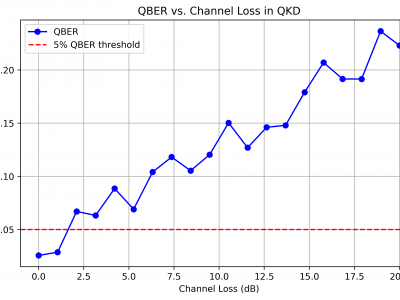
This dataset supports the research on hybrid quantum encryption by providing simulation results for Quantum Bit Error Rate (QBER) vs. Channel Loss in Quantum Key Distribution (QKD). The dataset includes numerical values used to generate the QBER vs. Channel Loss graph, which illustrates how increasing channel loss impacts quantum encryption performance.
- Categories:
179 Views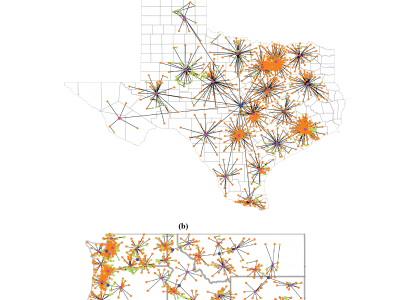
Modern power systems face growing risks from cyber-physical attacks, necessitating enhanced resilience due to their societal function as critical infrastructures. The challenge is that defense of large-scale systems-of-systems requires scalability in their threat and risk assessment environment for cyber-physical analysis including cyber-informed transmission planning, decision-making, and intrusion response. Hence, we present a scalable discrete event simulation tool for analysis of energy systems, called DESTinE.
- Categories:
208 Views
The National Institute of Standards and Technology (NIST) has recommended the use of stateful hash-based digital signatures for long-term applications that may require protection from future threats that use quantum computers. XMSS and LMS, the two approved algorithms, have multiple parameter options that impact digital signature size, public key size, the number of signatures that can be produced over the life of a keypair, and the computational effort to validate signatures. This collection of benchmark data is intended to support system designers in understanding the differences among
- Categories:
17 Views
This dataset provides the full list of security controls proposed in the article "Enhancing Cybersecurity in the Judiciary: Integrating Additional Controls into the CIS Framework". The dataset includes a detailed classification of security controls derived from the CIS Controls framework and additional measures specifically tailored to address cybersecurity challenges in the Judiciary. These controls enhance operational risk management, digital asset protection, and organizational resilience.
- Categories:
52 Views