Machine Learning

Automatic humor detection has interesting use cases in modern technologies, such as chatbots and virtual assistants. Existing humor detection datasets usually combined formal non-humorous texts and informal jokes with incompatible statistics (text length, words count, etc.). This makes it more likely to detect humor with simple analytical models and without understanding the underlying latent lingual features and structures.
- Categories:
 1104 Views
1104 Views
Dataset asscociated with a paper in Computer Vision and Pattern Recognition (CVPR)
"Object classification from randomized EEG trials"
If you use this code or data, please cite the above paper.
- Categories:
2348 Views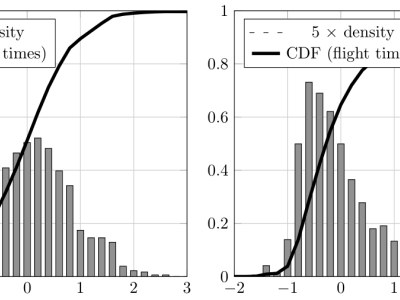
Dataset used in the article "On the shape of timing distributions in free text keystroke dynamics profiles". Contains CSV files with the timing features (hold times and flight times) of every keypress in three free text datasets used in previous studies, by the author (LSIA) and two other unrelated groups (KM from and PROSODY, subdivided in GAY, GUN, and REVIEW). The timing features are grouped by dataset, user, task, virtual key code, and feature. Two different languages are represented, Spanish in LSIA and English in KM and PROSODY.
- Categories:
415 Views
Datasets as described in the research paper "Intrusion Detection using Network Traffic Profiling and Machine Learning for IoT Applications".
There are two main dataset provided here, firstly is the data relating to the initial training of the machine learning module for both normal and malicious traffic, these are in binary visulisation format, compresed into the document traffic-dataset.zip.
- Categories:
6034 Views
The LEDNet dataset consists of image data of a field area that are captured from a mobile phone camera.
Images in the dataset contain the information of an area where a PCB board is placed, containing 6 LEDs. Each state of the LEDs on the PCB board represents a binary number, with the ON state corresponding to binary 1 and the OFF state corresponding to binary 0. All the LEDs placed in sequence represent a binary sequence or encoding of an analog value.
- Categories:
730 Views
For the task of detecting casualties and persons in search and rescue scenarios in drone images and videos, our database called SARD was built. The actors in the footage have simulate exhausted and injured persons as well as "classic" types of movement of people in nature, such as running, walking, standing, sitting, or lying down. Since different types of terrain and backgrounds determine possible events and scenarios in captured images and videos, the shots include persons on macadam roads, in quarries, low and high grass, forest shade, and the like.
- Categories:
10683 Views
Smart speakers and voice-based virtual assistants are core components for the success of the IoT paradigm. Unfortunately, they are vulnerable to various privacy threats exploiting machine learning to analyze the generated encrypted traffic. To cope with that, deep adversarial learning approaches can be used to build black-box countermeasures altering the network traffic (e.g., via packet padding) and its statistical information.
- Categories:
1461 Views
Human Neck movements data acquired using Meatwear - CPRO device - Accelerometer-based Kinematic data. Data fed to OpenSim simulation software extracted Kinematics and Kinetics (Muscles, joints - Forces, Acceleration, Position)
- Categories:
353 Views
Crowds express emotions as a collective individual, which is evident from the sounds that a crowd produces in particular events, e.g., collective booing, laughing or cheering in sports matches, movies, theaters, concerts, political demonstrations, and riots. Crowd sounds can be characterized by frequency-amplitude features, using analysis techniques similar to those applied on individual voices, where deep learning classification is applied to spectrogram images derived by sound transformations.
- Categories:
1421 Views
this is a data set for the speed range selection of a wind turbine inspection quadrotor
- Categories:
345 Views