Timing distributions in free text keystroke dynamics profiles
- Citation Author(s):
-
Nahuel González
 (Laboratorio de Sistemas de Información Avanzados)
(Laboratorio de Sistemas de Información Avanzados)
- Submitted by:
- Nahuel Gonzalez
- Last updated:
- DOI:
- 10.21227/ngv9-fa18
- Data Format:
 422 views
422 views
- Categories:
- Keywords:
Abstract
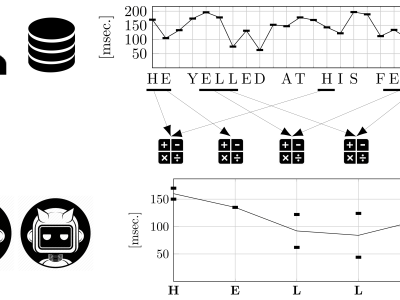
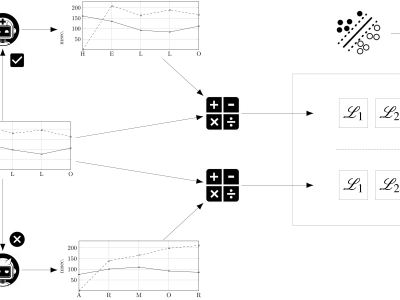
Dataset used in the article "On the shape of timing distributions in free text keystroke dynamics profiles". Contains CSV files with the timing features (hold times and flight times) of every keypress in three free text datasets used in previous studies, by the author (LSIA) and two other unrelated groups (KM from and PROSODY, subdivided in GAY, GUN, and REVIEW). The timing features are grouped by dataset, user, task, virtual key code, and feature. Two different languages are represented, Spanish in LSIA and English in KM and PROSODY.
The original dataset KM was used to compare anomaly-detection algorithms for keystroke dynamics in the article "Comparing anomaly-detection algorithms forkeystroke dynamic" by Killourhy, K.S. and Maxion, R.A. The original dataset PROSODY was used to find cues of deceptive intent by analyzing variations in typing patterns in the article "Keystroke patterns as prosody in digital writings: A case study with deceptive reviews and essay" by Banerjee, R., Feng, S., Kang, J.S., and Choi, Y.
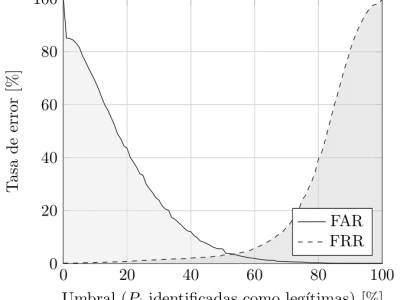
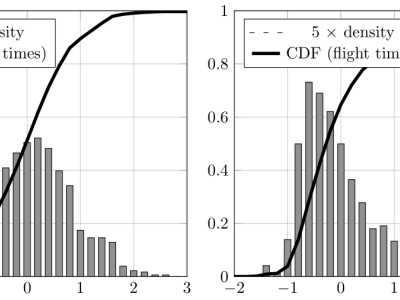
After evaluating seven distributions with two and three parameters separately, the results confirm the established use in the research community of the log normal distribution, in its two and three parameter variations, as excellent choices for modeling the shape of timings histograms in free text keystroke dynamics profiles. However, the log logistic distribution emerges as a clear winner among all two and three--parameter candidates, consistently surpassing the log normal and all the other candidates under the three evaluation criteria for both hold and flight times. It was also shown that tasks and topics do not influence enough the shape of timing histograms to distinguish them, even though the value of their parameters can, as can be seen in the article of Banerjee, R. et. al.
Instructions:
Each considered dataset contains several typing sessions for each user, consisting of a sequence of keystrokes where its hold times (down-up) and flight times (down-down) were recorded alongside other relevant information. All of the latter was ignored except for the name of the typing task. The rationale for this action was to observe how different tasks influence the best fitting distributions. Keystrokes were grouped on a per user basis, packing them independently of their sessions. Thus, a profile was built for each dataset, user, task, virtual key code, and feature, consisting of a set of timing values.
The files are named using the following convention: DATASET-TASK-USER-FEATURE-VK, and organized in folders according to their dataset and task. Due to the number of files being greater than a hundred thousand, they are packaged in the DISTRIBUTIONS.zip file. Five files, which are also included inside the package, are added to exemplify the naming convention. For example, KM-transcribed-USERs019-FT-VK32.csv contains the timing observations for the flight time (FT) of the space key (VK32, virtual key code 32) when pressed by the user s019 in the dataset KM, while he is carrying out a transcription task
Dataset Files
- DISTRIBUTIONS.zip (Size: 63.58 MB)
- GAY-Copy_1-USERA1BFO1ZAS64NUZ-FT-VK32.csv (Size: 464 bytes)
- GUN-Fake Essay-USERA1BFO1ZAS64NUZ-FT-VK32.csv (Size: 691 bytes)
- KM-transcribed-USERs019-FT-VK32.csv (Size: 2.73 KB)
- LSIA-FreeText-USER2078-FT-VK32.csv (Size: 22.53 KB)
- REVIEW-True Review-USERA1BFO1ZAS64NUZ-FT-VK32.csv (Size: 720 bytes)