Machine Learning

We provide a public available database for arcing event detection. We design a platform for arcing fault simulation. The arc simulation is carried out in our local lab under room temperature. A general procedure to collect the arcing and normal current and voltage wave, is designed, which consists of turning on the load, generating arc, stoping arc, turning off the load. The data is collected by a 16bit, 10KHz high resolution recorder and a 12bit, 64000Hz low resolution sensor.
- Categories:
 713 Views
713 Views
Time series univariate
- Categories:
1192 Views
Animal recognition is an active research topic in recent years. Horse’s recognition is an important task in the world and in order to promote horse’s recognition research, the Tunisian Research Groups in Intelligent Machines of University of Sfax (REGIM of Sfax) will provide the Tunisian Horses DataBase of Regim Lab’2015 (THoDBRL’2015) freely of charge to mainly horses’ face recognition researchers and to increase total of researches done to enhance animal recognition. This Database is used in [1].
- Categories:
913 Views
Animal detection is an active research topic in recent years. Horse’s face detection is an important task in the world and in order to promote horse’s detection and recognition research, the REGIM-Lab.: REsearch Groups in Intelligent Machines, ENIS, University of Sfax, Tunisia will provide the Tunisian Horse Detection Database (THDD) freely of charge to mainly horses’ face detection researchers and to increase total of researches done to enhance animal detection.
- Categories:
670 Views
Social images analysis from social networks is considered as one of the most popular social technologies. Social images analysis is an active research topic in recent years and in order to promotes social images’s analysis research, the REGIM-Lab.: REsearch Groups in Intelligent Machines, ENIS, University of Sfax, Tunisia provides the SmartCityZen database’2016 freely of charge to social images analysis researchers.
- Categories:
525 Views
Social images analysis from social networks is considered as one of the most popular social technologies. Social images analysis is an active research topic in recent years and in order to promotes social images’s analysis research, the REGIM-Lab.: REsearch Groups in Intelligent Machines, ENIS, University of Sfax, Tunisia provides the Sm@rtCityZen social images database freely of charge to social images analysis researchers.
- Categories:
427 Views
Biometric-based hand modality is considered as one of the most popular biometric technologies especially in forensic applications. Hand recognition is an active research topic in recent years and in order to promote hand’s recognition research, the REGIM-Lab.: REsearch Groups in Intelligent Machines, ENIS, University of Sfax, Tunisia provides the REgim Sfax Tunisian hand database (REST database) freely of charge to mainly hand and palmprint recognition researchers.
- Categories:
1952 Views
Here are some of the software vulnerability real-world data sets.
The original real-world data sets, collected by Lin et al. (https://github.com/DanielLin1986/TransferRepresentationLearning), which contain the source codes of vulnerable and non-vulnerable functions obtained from six real-world software projects, namely FFmpeg, LibTIFF, LibPNG, VLC and Pidgin. These datasets cover both multimedia and image application categories.
- Categories:
1362 Views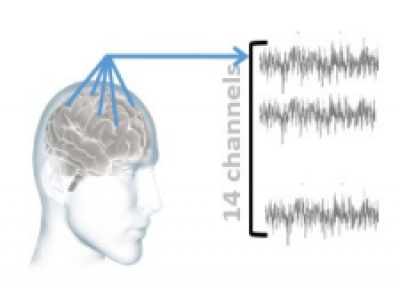
Anxiety affects human capabilities and behavior as much as it affects productivity and quality of life. It can be considered as the main cause of depression and suicide. Anxious states are easily detectable by humans due to their acquired cognition, humans interpret the interlocutor’s tone of speech, gesture, facial expressions and recognize their mental state. There is a need for non-invasive reliable techniques that perform the complex task of anxiety detection.
- Categories:
8654 Views
Character recognition has been widely understood as a means of mechanizing the process of understanding text in the written form to facilitate fast and efficient use of text. Indeed, text existing all around us presents information for peoples. However, tourists in foreign countries are unable to understand what indicate text on road signs, shop names, product advertisements, posters, etc. when they are unfamiliar with the native language of the visited country.
- Categories:
791 Views