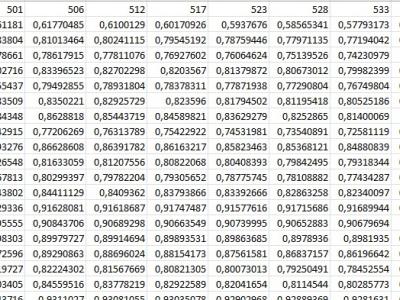
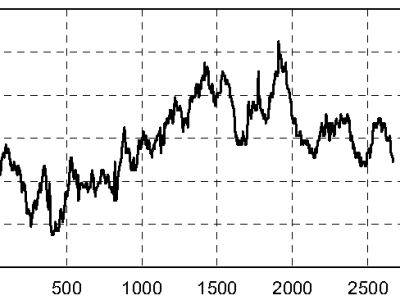
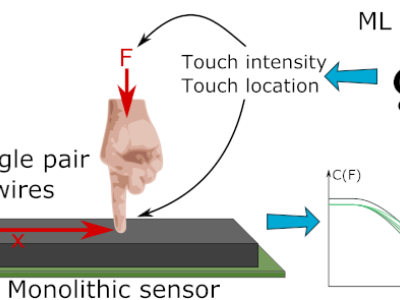
This dataset was acquired during the dissertation entitled "Optical Camera Communications and Machine Learning for Indoor Visible Light Positioning". This work was carried out in the academic year 2020/2021 at the Instituto de Telecomunicações in Aveiro in the scope of the Integrated Master in Electronics and Telecommunications Engineering at the Department of Electronics, Telecommunication and Informatics of the University of Aveiro.
- Categories: