Computational Intelligence

Distributed coordination function (DCF) is an important technique of medium access control (MAC), utilized by IEEE 802.11 wireless local area networks.
- Categories:
 404 Views
404 Views
Overview
- Categories:
1129 Views
Dockerfile plays an important role in the Docker-based containerization process, but many Dockerfile codes are infected with smells in practice. This dataset contains a collection of 6,334 projects to help developers gain some insights into the occurrence of Dockerfile smells. Those projects belong to 10 popular programming languages, i.e., Shell, Makefile, Ruby, PHP, Python, Java, HTML, CSS, JavaScript, and Go.
- Categories:
280 ViewsNetwork traffic analysis, i.e. the umbrella of procedures for distilling information from network traffic, represents the enabler for highly-valuable profiling information, other than being the workhorse for several key network management tasks. While it is currently being revolutionized in its nature by the rising share of traffic generated by mobile and hand-held devices, existing design solutions are mainly evaluated on private traffic traces, and only a few public datasets are available, thus clearly limiting repeatability and further advances on the topic.
- Categories:
1945 Views
This folder contains two csv files and one .py file. One csv file contains NIST ground PV plant data imported from https://pvdata.nist.gov/. This csv file has 902 days raw data consisting PV plant POA irradiance, ambient temperature, Inverter DC current, DC voltage, AC current and AC voltage. Second csv file contains user created data. The Python file imports two csv files. The Python program executes four proposed corrupt data detection methods to detect corrupt data in NIST ground PV plant data.
- Categories:
2891 Views
Even though intelligent systems such as Siri or Google Assistant are enjoyable (and useful) dialog partners, users can only access predefined functionality. Enabling end-users to extend the functionality of intelligent systems will be the next big thing. To promote research in this area we carried out an empirical study on how laypersons teach robots new functions by means of natural language instructions. The result is a labeled corpus consisting of 3168 submissions given by 870 subjects.
- Categories:
263 Views
This pre-trained Word2Vec model has 300-dimensional vectors for more than 0.5 million Nepali words and phrases. A separate Nepali language text corpus was created using the news contents freely available in the public domain. The text corpus contained more than 90 million running words. The "Nepali Text Corpus" can be accessed freely from http://dx.doi.org/10.21227/jxrd-d245.
- Categories:
3193 Views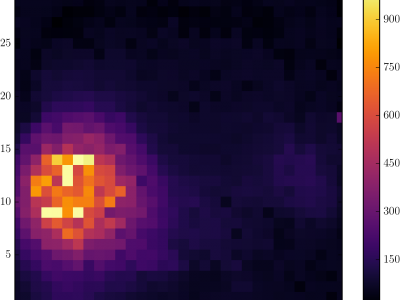
This data set comprises 4223 videos from a laser surface heat treatment process (also called laser heat treatment) applied to cylindrical workpieces made of steel. The purpose of the dataset is to detect anomalies in the laser heat treatment learning a model from a set of non-anomalous videos.
In the laser heat treatment, the laser beam is following a pattern similar to an "eight" with a frequency of 100 Hz. This pattern is sometimes modified to avoid obstacles in the workpieces.
- Categories:
707 Views
This is the dataset for the manuscript entitled "Physics-prior Bayesian neural networks in semiconductor processing", IEEE Access
- Categories:
223 Views
This contains data for ISFET based pH sensor drift compensation using machine learning techniques
- Categories:
366 Views