Computational Intelligence

Database for FMCW THz radars (HR workspace) and sample code for federated learning
- Categories:
 1496 Views
1496 Views
Reinforcement Learning (RL) agents can learn to control a nonlinear system without using a model of the system. However, having a model brings benefits, mainly in terms of a reduced number of unsuccessful trials before achieving acceptable control performance. Several modelling approaches have been used in the RL domain, such as neural networks, local linear regression, or Gaussian processes. In this article, we focus on a technique that has not been used much so far:\ symbolic regression, based on genetic programming.
- Categories:
292 Views
Real life business processes change over time, in both planned and unexpected ways. These changes over time are called concept drifts and its detection is a big challenge in process mining since the inherent complexity of the data makes difficult distinguishing between a change and an anomalous execution. The following logs were generated synthetically in order to prove the quality of different concept drift detection algorithms.
- Categories:
950 Views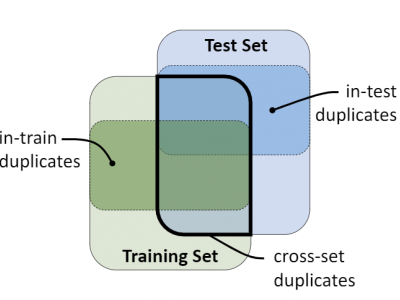
Code duplicates in large code corpora have adverse effects on the evaluation and use of machine learning models that rely on them. Most existing corpora suffer from this problem to some extent. This dataset contains a "duplication" index for some of the existing corpora in Big Code research. The method for collecting this dataset is described in "The Adverse Effects of Code Duplication in Machine Learning Models of Code" by Allamanis [ArXiV, to appear in SPLASH 2019].
- Categories:
676 Views
This dataset contains a sequence of network events extracted from a commercial network monitoring platform, Spectrum, by CA. These events, which are categorized by their severity, cover a wide range of events, from a link state change up to critical usages of CPU by certain devices. Regarding the layers they cover, they are focused on the physical, network and application layer. As such, the whole set gives a complete overview of the network’s general state.
- Categories:
890 Views
The compressed file contains:
- Data files in spreadsheet format from three different networks (friendship, companionship and acquaintances).
- Analysis files from UCINET, Pajek, Cytoscape and Gephi.
It is thus possible to corroborate the results mentioned in different studies that refer to these data.
- Categories:
449 Views
OntoSNAQA is the name that combines Social Network Analysis (SNA), People and Questionnaires (Question and Answers - QA).
This ontology will be updated in this project of github and in the url http://www.jabenitez.com/ontologies/OntoSNAQA.owl.
It's an ontology that combines three different domains:
- People
- Questionnaires
- Social Network Analysis terms
- Categories:
253 Views
We introduce a benchmark of distributed algorithms execution over big data. The datasets are composed of metrics about the computational impact (resource usage) of eleven well-known machine learning techniques on a real computational cluster regarding system resource agnostic indicators: CPU consumption, memory usage, operating system processes load, net traffic, and I/O operations. The metrics were collected every five seconds for each algorithm on five different data volume scales, totaling 275 distinct datasets.
- Categories:
1886 Views
SDTwittC consists of 200 authors evenly balanced by gender (100 for each). We identified the gender of the tweeters via their names and profile pictures. As potential copy-and-paste texts, both tweets and retweets are discarded in the first place. Only replies are compiled. The number of replies for each author varies from hundreds to thousands. Male authors produced 233926 replies whereas 219740 replies are generated by the female group
- Categories:
894 Views
This dataset was created based on the paper 'Andras Hajdu, Gyorgy Terdik, Attila Tiba, and Henrietta Toman: A stochastic approach to handle knapsack problems in the creation of ensembles'.To summarize our experimental setup for UCI binary classification problems, we have considered base classifiers perceptron, decision tree, Levenberg-Marquardt feedforward neural network, random neural network, and discriminative restricted Boltzmann machine classifier for the 5 UCI datasets MAGIC Gamma Telescope, HIGGS, EEG EyeState, Musk (Version 2), and Spambase; datasets of large cardinalities were sele
- Categories:
299 Views