Communications

The Human voice Natural Language from On-demand media (HENLO) dataset is a high-quality emotional speech dataset created to address the need for representative and realistic data in speech emotion recognition research. Unlike many existing datasets, which rely on simulated emotions performed by untrained speakers or directed participants, HENLO sources its data from professionally produced films and podcasts available on Media On-Demand (MOD).
- Categories:
 220 Views
220 Views
—As part of Internet of thing networks, visible light communication (VLC) technology has excelled in recent years. When compared to traditional radio frequency (RF) technology, VLC offers the advantages of abundant and unlicensed spectrum bands, no RF-induced interference, inherent security, safety and energy efficiency, making it an excellent choice for short-range communication applications. However, the performance of VLC is severely limited under the non-line-of-sight (NLOS) links.
- Categories:
140 Views
The given data contains the results from laboratory trials related to the paper "Optimizing Congestion Management andEnhancing Resilience in Low-Voltage Grids Using OPF and MPC Control Algorithms Through Edge Computing and IEC 61850 Standards" currently in publication in IEEE Access.
- Categories:
231 Views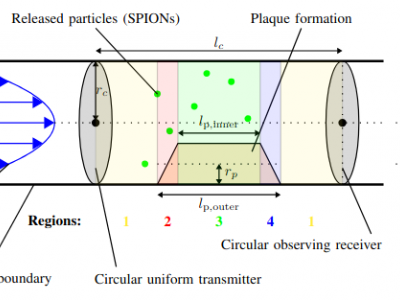
This dataset contains the simulation results for the microfluidic molecular simulation for advanced plaque modeling using the OpenFOAM MPPIC solver. In addition to the simulation results, first simulation results for fluid-solid interaction are uploaded using the solids4foam toolbox.
Publication:
- Categories:
82 Views
CAMARA is an open-source project which is part of Linux Foundation. It aims at defining service APIs by combining network APIs, over an operator domain. CAMARA works in close collaboration with the GSMA Operator Platform Group to align API requirements and definitions, and to publish APIs.
IEEE 5G testbed supports the CAMARA initiative and provides these APIs for data privacy and regulatory requirements and facilitate application to network integration.
CAMARA APIs allow to tackle several types of business use cases leveraging 4G/5G network capabilities.
- Categories:
355 Views
Internet telephony consists of a combination of hardware and software that enables you to
use the Internet as the transmission medium for telephone calls. For users who have free,
or fixed-price Internet access, Internet telephony software essentially provides free
telephone calls anywhere in the world. In its simplest form, PC-to-PC Internet telephony
can be as easy as hooking up a microphone to your computer and sending your voice
through a cable modem to a person who has Internet telephony software that is
- Categories:
56 Views
Modern, industrial automation is unthinkable without wireless communications. Thereby, wireless links provide the necessary flexibility for industrial real-time applications. On the other side, these applications need at the same time a wireless communications link that works ultra-reliably. In communications systems, unreliability can be traced back to the fading behavior of the wireless radio channel as the medium between the communicating entities.
- Categories:
156 Views
This dataset used in the research paper "JamShield: A Machine Learning Detection System for Over-the-Air Jamming Attacks." The research was conducted by Ioannis Panitsas, Yagmur Yigit, Leandros Tassiulas, Leandros Maglaras, and Berk Canberk from Yale University and Edinburgh Napier University.
For any inquiries, please contact Ioannis Panitsas at ioannis.panitsas@yale.edu.
- Categories:
327 Views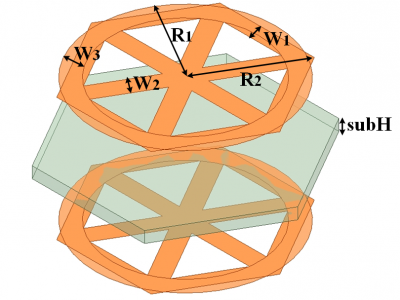
The design of this ASS structure is based on a dual-layer frequency-selective surface (FSS), where the unit cell consists of a single substrate and two metal layers. This structure achieves resonant transmission at specific oblique angles while blocking electromagnetic (EM) waves at other angles. In addition, the equivalent circuit model (ECM) is utilized to analyze the proposed structure, revealing the influence of oblique incidenc on circuit parameters.
- Categories:
199 Views
This dataset consists of network packet traces collected in 2023 on the 5G infrastructure deployed at Chalmers University of Technology.
The dataset includes 1,912 pcap files, distributed across 8 folders. Each pcap file captures 1 minute of encrypted network traffic generated by one of the following 8 popular mobile applications:
- Categories:
963 Views