Artificial Intelligence

DRL DP USV
- Categories:
 47 Views
47 Views
A dataset of Global Positioning System (GPS) spoofing attacks is presented in this article. This dataset includes data extracted from authentic GPS signals collected from different locationsto emulate a moving and a static autonomous vehicle using a universal software radio peripheral unit configured as a GPS receiver. During the data collection, 13 features are extracted from eight-parallel channels at different receiver stages (i.e., acquisition, tracking, and navigation decoding).
- Categories:
3410 Views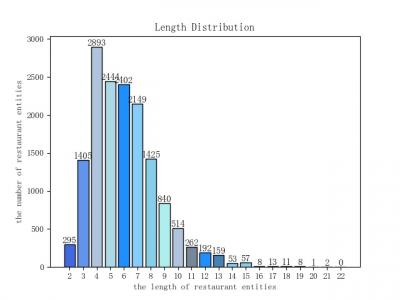
The data set sentences are evenly distributed in length
- Categories:
54 Views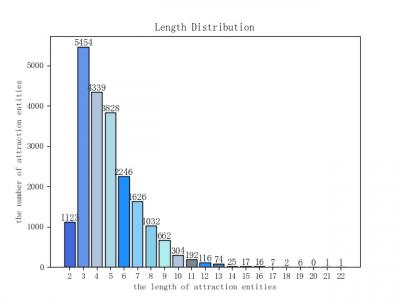
The data set sentences are evenly distributed
- Categories:
38 Views
The Paddy Doctor dataset contains 16,225 labeled paddy leaf images across 13 classes (12 different paddy diseases and healthy leaves). It is the largest expert-annotated visual image dataset to experiment with and benchmark computer vision algorithms. The paddy leaf images were collected from real paddy fields using a high-resolution (1,080 x 1,440 pixels) smartphone camera. The collected images were carefully cleaned and annotated with the help of an agronomist.
- Categories:
10880 Views
The Research Paper "Detection of Bicep Form Using Myoware and Machine Learning" based on the novel dataset has been recently accepted in September 2022 and is being published in SCOPUS Indexed SPRINGER Book Series “Lecture Notes in Networks and Systems”
- Categories:
1305 Views
Prior researches have shown the potential that WiFi signals could be used for human activities recognition (HAR), or monitor a person's gait for human identification (HI). Recently researchers pay more attention to the impact of environmental factors such as activity orientation, walking trajectory, WiFi device location, etc. on the HAR or HI tasks' performance.
- Categories:
451 Views
The data set is about different parameters that are important for monitoring the "Engine Condition" and predicting its status as "Engine is Good or Bad".
Keywords-:
1.Engine rpm
2 Lub oil temperature
3.Coolant temperature
4.Fuel pressure
5.Lub oil pressure
6.Coolant pressure
- Categories:
2896 Views
The problem of effective disposal of the trash generated by people has rightfully attracted major interest from various sections of society in recent times. Recently, deep learning solutions have been proposed to design automated mechanisms to segregate waste. However, most datasets used for this purpose are not adequate. In this paper, we introduce a new dataset, TrashBox, containing 17,785 images across seven different classes, including medical and e-waste classes which are not included in any other existing dataset.
- Categories:
976 Views
Guava fruit production is one of the main sources of economic growth in Asian countries, the world production of guava in 2019 was 55 million tons. Guava disease is an important factor in economic loss as well as quantity and quality of guava. The original guava fruit disease dataset consist of 38 images of phytophthora, 30 images of root and 34 images of scab guava disease with 650x650x3 pixel.
- Categories:
1156 Views