Artificial Intelligence

Recognition and classification of currency is one of the important task. It is a very crucial task for visually impaired people. It helps them while doing day to day financial transactions with shopkeepers while traveling, exchanging money at banks, hospitals, etc. The main objectives to create this dataset were:
1) Create a dataset of old and new Indian currency.
2) Create a dataset of Thai Currency.
3) Dataset consists of high-quality images.
- Categories:
 3802 Views
3802 Views
INDIA is the second-largest fruit and vegetable exporter in the world after China. It ranked first in the production of Bananas, Papayas, and Mangoes. Public datasets of fruits are available but they are limited to general fruit classes and failed to classify the fruits according to the fruit quality. To overcome this problem, we have created a dataset named FruitsGB (Fruits Good/Bad) dataset.
- Categories:
6477 Views
Recently, self-driving vehicles have been introduced with several automated features including lane-keep assistance, queuing assistance in traffic-jam, parking assistance and crash avoidance. These self-driving vehicles and intelligent visual traffic surveillance systems mainly depend on cameras and sensors fusion systems.
- Categories:
4227 Views
Load identification have shown significant performance gains in Chinese smart grids. Most existing load identification algorithms are based on electrical characteristics of steady or transient state, which are therefore limited by feature selection and analyzing pattern.
- Categories:
1322 Views
Presented here is a dataset used for our SCADA cybersecurity research. The dataset was built using our SCADA system testbed described in our paper below [*]. The purpose of our testbed was to emulate real-world industrial systems closely. It allowed us to carry out realistic cyber-attacks.
- Categories:
2221 Views
The dataset comprises of image file s of size 20 x 20 pixels for various types of metals and non-metal.The data collected has been augmented, scaled and modified to represent a number a training set dataset.It can be used to detect and identify object type based on material type in the image.In this process both training data set and test data set can be generated from these image files.
- Categories:
1971 Views
Dataset for the paper entitled "Interactive Dual Attention Network for Text Sentiment Classification"
- Categories:
145 Views
The Dataset
We introduce a novel large-scale dataset for semi-supervised semantic segmentation in Earth Observation: the MiniFrance suite.
- Categories:
6318 Views
We introduce a new database of voice recordings with the goal of supporting research on vulnerabilities and protection of voice-controlled systems (VCSs). In contrast to prior efforts, the proposed database contains both genuine voice commands and replayed recordings of such commands, collected in realistic VCSs usage scenarios and using modern voice assistant development kits.
- Categories:
1797 Views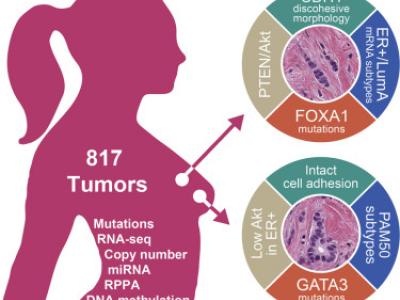
Invasive lobular carcinoma (ILC) is the second most prevalent histologic subtype of invasive breast cancer. Here, we comprehensively profiled 817 breast tumors, including 127 ILC, 490 ductal (IDC), and 88 mixed IDC/ILC. Besides E-cadherin loss, the best known ILC genetic hallmark, we identified mutations targeting PTEN, TBX3 and FOXA1 as ILC enriched features. PTEN loss associated with increased AKT phosphorylation, which was highest in ILC among all breast cancer subtypes. Spatially clustered FOXA1 mutations correlated with increased FOXA1 expression and activity.
- Categories:
626 Views