Artificial Intelligence

The SINEW (Sensors in Home for Elderly Wellbeing) dataset consists of 15 high-level biomarker features, derived from raw sensor readings collected by in-home sensors used for predictive modeling research: SINEW 15 - Monthly Biomarker.
This dataset was collected for a study focused on the early detection of mild cognitive impairment, providing an opportunity for timely intervention before it progresses to Alzheimer's disease.
- Categories:
 115 Views
115 Views
# Top 100 YouTube Channels Dataset
## Overview
This dataset provides comprehensive information about the top 100 YouTube channels based on subscriber count. It offers valuable insights into the most popular content creators on the platform, their performance metrics, and channel details.
## Dataset Contents
The dataset includes the following information for each channel:
- Channel ID
- Title
- Custom URL
- Subscriber Count
- Video Count
- View Count
- Category
- Country
- Categories:
72 Views
This study presents a English-Luganda parallel corpus comprising over 2,000 sentence pairs, focused on financial decision-making and products. The dataset draws from diverse sources, including social media platforms (TikTok comments and Twitter posts from authoritative accounts like Bank of Uganda and Capital Markets Uganda), as well as fintech blogs (Chipper Cash and Xeno). The corpus covers a range of financial topics, including bonds, loans, and unit trust funds, providing a comprehensive resource for financial language processing in both English and Luganda.
- Categories:
176 Views
This dataset, mentioned in paper "MS2A: Memory Storage-to-Adaptation for Cross-domain Few-annotation Object Detection" and prepared for Cross-domain Few-annotation Object Detection task, consists of two cross-domain scenarios: Indus-S to Indus-T1 and Indus-S to Indus-T2. In detail, Indus-S consists of 4614 images for training and 1153 images for validation; Indus-T1 and Indus-T2 have 269 and 432 images for validation respectively. For the training data of Indus-T1 and Indus-T2, we introduce three different settings: 10-anno, 30-anno and 50-anno.
- Categories:
95 Views
In order to realize intelligent and accurate campus risk detection, this paper proposes an improved YOLOv10 algorithm that integrates Self-Calibrated Illumination algorithm. The algo-rithm optimizes the loss function by introducing an auxiliary bounding box, and accelerates model convergence. StarNet is employed to enhance the original network structure, feature extraction capability, and decrease parameter count and calculations.
- Categories:
43 Views
Two-year price movements from 01/01/2014 to 01/01/2016 of 88 stocks are selected to target, coming from all the 8 stocks in the Conglomerates sector and the top 10 stocks in capital size in each of the other 8 sectors. The full list of 88 stocks and their companies selected from 9 sectors is available in StockTable, a facsimile of the paper appendix appendix_table_of_target_stocks.pdf.
- Categories:
34 Views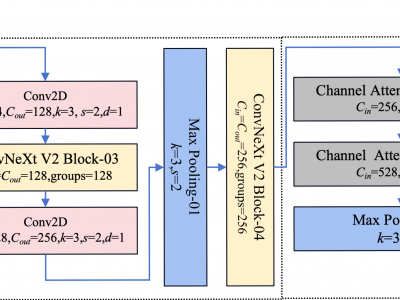
Underwater acoustic target classification (UATC) aims to identify the type of unknown acoustic sources using passive sonar in oceanic remote sensing scenarios. However, the variability of underwater acoustic environment and the presence of complex background noises create significant obstacles to improving accuracy of UATC. To address these challenges, we develop an innovative deep neural network (DNN) algorithm integrated by multiscale feature extractor and efficient channel attention mechanism.
- Categories:
570 Views
Recent advances in generative visual content have led to a quantum leap in the quality of artificially generated Deepfake content. Especially, diffusion models are causing growing concerns among communities due to their ever-increasing realism. However, quantifying the realism of generated content is still challenging. Existing evaluation metrics, such as Inception Score and Fréchet inception distance, fall short on benchmarking diffusion models due to the versatility of the generated images.
- Categories:
81 Views
This data ia small sample set from the purchase order data catalog of state of california publicaly available at https://catalog.data.gov/dataset/purchase-order-data. From this source, we take a sample of 50,000 entries. The data provides comprehensive details about various purchase orders issued during this period. The dataset comprises 32 columns, capturing information about each purchase order. This dataset is rich in information and provides a valuable resource for item UNSPSC categorization.
- Categories:
59 Views
Experiment Details:
- Categories:
1490 Views