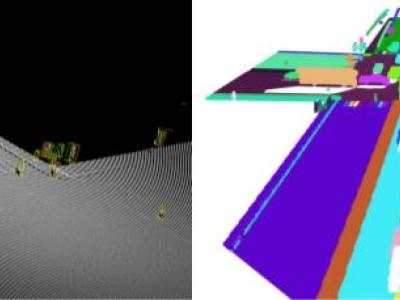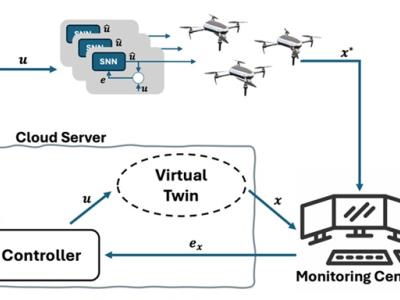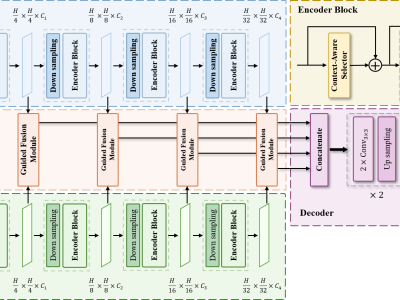
This upload contains code related to the article and is intended to help IEEE DataPort users understand how to use and reproduce our research methods. The code implements Remote Sensing image change Detection Network (CGLCS-Net) based on deep learning, including global-local context-aware selector (GLCAS) and subspace Self-Attention Fusion module (SSAF).
- Categories: