*.csv

The dataset attached is recordings done for 5 parameters to ascertain physical soil composition. Data was collected between March 2021 and April 2021. This dataset is the raw data.
- Categories:
 2751 Views
2751 Views
This dataset is proposed for human activity recognition tasks. The static activities including sitting, standing, and laying, as well as walking, running, cycling, and walking upstairs/downstairs. Each activity lasts for 2 minutes, 50 subjects were involved in the experiments.
- Categories:
591 Views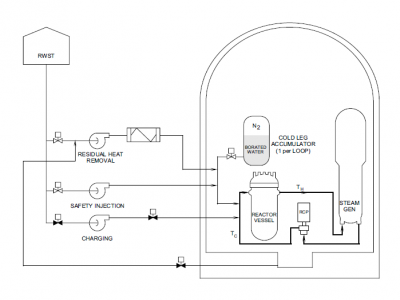
We introduce a novel dataset specifically designed for the evaluation of “alarm flood classification” (AFC) methods within process plants. The growing complexity of industrial systems and the heightened demands for operational safety and efficiency underscore the critical need for advanced diagnostic tools capable of handling alarm floods—situations where numerous alarms are triggered simultaneously.
- Categories:
313 Views
The data acquisition process begins with capturing EEG signals from 20 healthy skilled volunteers who gave their written consent before performing the experiments. Each volunteer was asked to repeat an experiment for 10 times at different frequencies; each experiment was trigger by a visual stimulus.
- Categories:
35878 Views
This is an initiative developed by FIEC-ESPOL professors. Temperature and Speed Control Lab (TSC-LAB) is an open source hardware development.
- Categories:
98896 Views
This Data contains measurements on reading and writing data to OPC UA servers directly and via REST and GraphQL interfaces. Each measurement is conducted 50 times. Measurements include reading a single value and reading a value 50 times. Measurements are conducted with Wireshark and the csv files are exported from it.
- Categories:
138 Views
A wide range of wearable sensors exist on the market for continuous physiological health monitoring. The type and scope of health data that can be gathered is a function of the sensor modality. Blumio presents a dataset of synchronized data from a reference blood pressure device along with several wearable sensor types: PPG, applanation tonometry, and the Blumio millimeter-wave radar. Data collection was conducted under set protocol with subjects seated at rest. 115 study subjects were included (age range 20-67 years), resulting in over 19 hours of data acquired.
- Categories:
3668 Views
More than 40% of energy resources are consumed in the residential buildings, and most of the energy is used for heating. Improving the energy efficiency of residential buildings is an urgent problem. The collected data is intended to study a dependence of the dynamics heat energy supply from outside temperature and houses characteristics, such as walls material, year of construction, floors amount, etc. This study will support the development of methods for comparing thermal characteristics of residential buildings and carry out recommendations for the energy efficiency increases.
- Categories:
456 Views
More than 40% of energy resources are consumed in the residential buildings, and most of the energy is used for heating. Improving the energy efficiency of residential buildings is an urgent problem. The collected data is intended to study a dependence of the dynamics heat energy supply from outside temperature and houses characteristics, such as walls material, year of construction, floors amount, etc. This study will support the development of methods for comparing thermal characteristics of residential buildings and carry out recommendations for the energy efficiency increases.
- Categories:
1036 Views
Recent US Census Data the American Community Survey,
- Categories:
475 Views