*.csv

Brain-Computer Interface (BCI) has become an established technology to interconnect a human brain and an external device. One of the most popular protocols for BCI is based on the extraction of the so-called P300 wave from EEG recordings. P300 wave is an event-related potential with a latency of 300 ms after the onset of a rare stimulus. In this paper, we used deep learning architectures, namely convolutional neural networks (CNNs), to improve P300-based BCIs.
- Categories:
 980 Views
980 Views
Time-varying positions, velocities, and orbital elements of 1584 satellites in a simulated megaconstellation modelled on Phase 1 of SpaceX’s Starlink.
- Categories:
754 Views
The Android Malware Detection Dataset consists of different flavors and diversity of malware APK files that can be used for malware detection using machine learning. It is my research work and if you use this dataset please cite my work in your research papers.
- Categories:
824 Views
With the motivation of no good data sources available for all diseases (from generic to chronic) and their treatment courses, a new dataset is synthesized by exploring several medical websites and resources. It provides the precaution list corresponding to over 1000+ diaganosis. prec\_t.csv : (did, diagnose, pid) = (Disease identifier, Disease name, treatment course). This dataset can be utilized for many machine learning or deep learning based healthcare applications.
- Categories:
6588 Views
Dataset used in the article "An Ensemble Method for Keystroke Dynamics Authentication in Free-Text Using Word Boundaries". For each user and free-text sample of the companion dataset LSIA, contains a CSV file with the list of words in the sample that survived the filters described in the article, together with the CSV files with training instances for each word. The source data comes from a dataset used in previous studies by the authors. The language of the free-text samples is Spanish.
- Categories:
502 Views
We present here an annotated thermal dataset which is linked to the dataset present in https://ieee-dataport.org/open-access/thermal-visual-paired-dataset
To our knowledge, this is the only public dataset at present, which has multi class annotation on thermal images, comprised of 5 different classes.
This database was hand annotated over a period of 130 work hours.
- Categories:
1103 Views
A promising technique to realize augmented reality on future light-weight glasses is to offload computationally extensive rendering tasks to the cloud. This however places considerable demands on the network as well as the air interface with respect to latency, reliability and throughput. For evaluation of these architectures and for traffic modelling, a dataset is provided, which contains realistic payloads of cloud-rendered augmented reality in form of video files.
- Categories:
438 Views
The data set contains inspections conducted by the Norwegian Labour Inspection Authority (NLIA) between 2012 and 2019. Each row in the dataset contains a control point, non-compliance indicator for the control point and industry code / municipality / county of the inspected organisation.
- Categories:
364 Views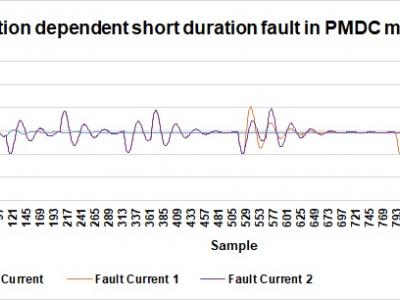
PMDC motor finds wide application in electric unity systems. Performance of the motor depends on overall mechnical vibrations. These two aspects are inter related. Also the structural platform or foundations play important role in these regards. Too much vibration often cause short circuit for short period. This data set presents sample vibration dependent short circuit data of current signals along with normal current for a PMDC with 12 volt supply.
- Categories:
372 Views
The CoVID19-FNIR dataset contains news stories related to CoVID-19 pandemic fact-checked by expert fact-checkers. CoVID19-FNIR is a CoVID-19-specific dataset consisting of fact-checked fake news scraped from Poynter and true news from the verified Twitter handles of news publishers. The data samples were collected from India, The United States of America, and European regions and consist of online posts from social media platforms between February 2020 to June 2020. The dataset went through prepossessing steps that include removing special characters and non-vital information.
- Categories:
6648 Views