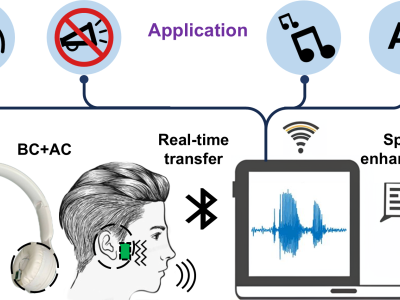
To support research on multimodal speech emotion recognition (SER), we developed a dual-channel emotional speech database featuring synchronized recordings of bone-conducted (BC) and air-conducted (AC) speech. The recordings were conducted in a professionally treated anechoic chamber with 100 gender-balanced volunteers. AC speech was captured via a digital microphone on the left channel, while BC speech was recorded from an in-ear BC microphone on the right channel, both at a 44.1 kHz sampling rate to ensure high-fidelity audio.
- Categories: